įŲėŗ(j©¼)╦ŃĄ─│÷¼F(xi©żn)Ż¼╩╣Ą├öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)ėą┴╦ą┬Ą─░l(f©Ī)š╣ĘĮŽ“Ż¼ę▓╩╣Ą├ą┬ę╗┤·Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)│╔×ķ┐╔─▄ĪŻįŲėŗ(j©¼)╦Ń╩Ū─▄ē“╠ß╣®äė(d©░ng)æB(t©żi)┘Yį┤Īó╠ōöM╗»║═Ė▀┐╔ė├Ą─ėŗ(j©¼)╦ŃŲĮ┼_(t©ói)ĪŻįŲėŗ(j©¼)╦ŃŲĮ┼_(t©ói)┐╔▒╗ė├üĒķ_░l(f©Ī)Ė▀ąį─▄Ą─æ¬(y©®ng)ė├│╠ą“ĪŻĄ½╩Ūī”ė┌öĄ(sh©┤)ō■(j©┤)═┌Š“üĒšfŻ¼║Ż┴┐öĄ(sh©┤)ō■(j©┤)▒Š╔ĒŠ▀ėąįļ┬ĢĪó«Éśŗ(g©░u)Īó╦ŃĘ©Å═(f©┤)ļsĪó╝╝ąg(sh©┤)Å═(f©┤)ļsĄ╚å¢Ņ}Ż¼Č°¼F(xi©żn)į┌Ą─įŲėŗ(j©¼)╦Ńķ_░l(f©Ī)ŲĮ┼_(t©ói)▓óø]ėą╠ß╣®öĄ(sh©┤)ō■(j©┤)ęÄ(gu©®)╝sĄ╚╣”─▄ĪŻę“┤╦╬─š┬═©▀^ī”ė┌öĄ(sh©┤)ō■(j©┤)═┌Š“ĪóįŲėŗ(j©¼)╦ŃĄ─įö╝Ü(x©¼)├Ķ╩÷║═Ęų╬÷Ż¼╠ß│÷┴╦╗∙ė┌įŲėŗ(j©¼)╦ŃĄ─öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)ĪŻįōŲĮ┼_(t©ói)╝▄śŗ(g©░u)╗∙ė┌įŲėŗ(j©¼)╦ŃĄ─╗∙ĄA(ch©│)─▄┴”Ż¼▓óĘ¹║ŽįŲėŗ(j©¼)╦Ń▄ø╝■╝┤Ę■äš(w©┤)(SaaS)Ą─įO(sh©©)ėŗ(j©¼)└Ē─ŅĪŻįōŲĮ┼_(t©ói)▀Ć─▄śO┤¾£p╔┘▀\(y©┤n)ĀI╔╠ĪóŲ¾śI(y©©)į┌öĄ(sh©┤)ō■(j©┤)═┌Š“╝╝ąg(sh©┤)╔ŽĄ─═Č╚ļ▓ó─▄╝ė┐ņŲõ═┌Š“śI(y©©)äš(w©┤)Ą─═Ų│÷Ż¼┐sČ╠čą░l(f©Ī)ų▄Ų┌Ż¼▀M(j©¼n)ę╗▓Į╠ßĖ▀«a(ch©Żn)ŲĘ╩šęµĪŻ
ĪĪĪĪ1.╗∙ė┌įŲėŗ(j©¼)╦ŃĄ─öĄ(sh©┤)ō■(j©┤)═┌Š“▓▀┬į
ĪĪĪĪ1.1 öĄ(sh©┤)ō■(j©┤)═┌Š“
ĪĪĪĪöĄ(sh©┤)ō■(j©┤)═┌Š“╩Ūę╗éĆ(g©©)Å─┤¾┴┐Ą─Īó▓╗═Ļ╚½Ą─Īóėąįļ┬ĢĄ─Īó─Ż║²Ą─ĪóļSÖC(j©®)Ą─īŹ(sh©¬)ļHöĄ(sh©┤)ō■(j©┤)ųą╠ß╚Īļ[║¼į┌ŲõųąĄ─Ą½Š▀ėąØōį┌īŹ(sh©¬)ė├ą┼Žó║═ų¬ūR(sh©¬)Ą─▀^│╠ĪŻÅ─öĄ(sh©┤)ō■(j©┤)═┌Š“Ą─Č©┴x┐╔ęį┐┤│÷öĄ(sh©┤)ō■(j©┤)═┌Š“╩Ūų¬ūR(sh©¬)░l(f©Ī)¼F(xi©żn)ŅI(l©½ng)ė“Ą─ę╗éĆ(g©©)ųžę¬╝╝ąg(sh©┤)Ż¼╦³╔µ╝░ĄĮ╚╦╣żųŪ─▄ĪóÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)Īó─Ż╩ĮūR(sh©¬)äeĪóĮy(t©»ng)ėŗ(j©¼)īW(xu©”)Ą╚Ė▀╝╝ąg(sh©┤)ŅI(l©½ng)ė“Ż¼Š▀¾w╝╝ąg(sh©┤)░³└©╠žš„╗»ĪóĻP(gu©Īn)┬ō(li©ón)ĪóŠ█ŅÉĪóŅA(y©┤)£yĘų╬÷Ą╚ĪŻöĄ(sh©┤)ō■(j©┤)═┌Š“į┌╗ź┬ō(li©ón)ŠW(w©Żng)ĪóęŲäė(d©░ng)╗ź┬ō(li©ón)ŠW(w©Żng)ĪóļŖą┼ĪóĮ╚┌Īó┐ŲīW(xu©”)蹊┐Ą╚ŅI(l©½ng)ė“Ą├ĄĮ┴╦ÅVĘ║Ą─æ¬(y©®ng)ė├Ż¼└²╚ńFacebook Ą─║├ėč═Ų╦]Īó║═╠įīÜŠW(w©Żng)Ą─╔╠ŲĘ═Ų╦]ĪóŃyąąĄ─Ę└Ų█įpĘų╬÷Ą╚ĪŻé„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“╝╝ąg(sh©┤)Į©┴óį┌ĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)ÄņĪóöĄ(sh©┤)ō■(j©┤)é}Äņų«╔ŽĄ─Ż¼ī”öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąėŗ(j©¼)╦ŃŻ¼šę│÷ļ[▓žį┌öĄ(sh©┤)ō■(j©┤)ųąĄ──Żą═╗“ĻP(gu©Īn)ŽĄŻ¼▓óį┌┤¾ęÄ(gu©®)─ŻĄ─öĄ(sh©┤)ō■(j©┤)╔Ž▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)įLå¢║═Įy(t©»ng)ėŗ(j©¼)ėŗ(j©¼)╦ŃŻ¼š¹éĆ(g©©)═┌Š“Ą─▀^│╠ąĶꬎ¹║─┤¾┴┐Ą─ėŗ(j©¼)╦Ń┘Yį┤ęį╝░┤µā”(ch©│)┘Yį┤ĪŻ
ĪĪĪĪļSų°įŲĢr(sh©¬)┤·Ą─ĄĮüĒ║═ęŲäė(d©░ng)╗ź┬ō(li©ón)ŠW(w©Żng)Ą─┐ņ╦┘░l(f©Ī)š╣Ż¼öĄ(sh©┤)ō■(j©┤)ęÄ(gu©®)─ŻÅ─MBĪó╝ē░l(f©Ī)š╣ĄĮTBĪóPB ╝ē╔§ų┴EBĪóZB ╝ēŻ¼▓óŪę├µ┼Rų°TB ╝ēĄ─į÷ķL╦┘Č╚Ż¼öĄ(sh©┤)ō■(j©┤)═┌Š“Ą─ę¬Ū¾║═Łh(hu©ón)Š│ę▓ūāĄ├įĮüĒįĮÅ═(f©┤)ļsŻ¼Å─Č°ą╬│╔“öĄ(sh©┤)ō■(j©┤)┴┐Ą─╝▒äĪ┼“├ø”║═“ öĄ(sh©┤)ō■(j©┤)╔ŅČ╚Ęų╬÷ąĶŪ¾Ą─į÷ķL”▀@ā╔┤¾┌ģä▌Ż¼╩╣Ą├40 ─ĻüĒę╗ų▒▀mė├Ą─öĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)╝▄śŗ(g©░u)į┌║Ż┴┐öĄ(sh©┤)ō■(j©┤)═┌Š“ĘĮ├µ’@Ą├┴”▓╗Å─ą─ĪŻ
ĪĪĪĪŠC║Ž╔Ž╩÷Ż¼é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“╝╝ąg(sh©┤)╝░Ųõ¾wŽĄ╝▄śŗ(g©░u)į┌įŲĢr(sh©¬)┤·Ą─║Ż┴┐öĄ(sh©┤)ō■(j©┤)ųąęčĮø(j©®ng)│÷¼F(xi©żn)┴╦▓╗╔┘å¢Ņ}Ż¼Ųõųą╩ūŽ╚╩Ū═┌Š“ą¦┬╩Ą─å¢Ņ}Ż¼é„Įy(t©»ng)Ą─╗∙ė┌å╬ÖC(j©®)Ą─═┌Š“╦ŃĘ©╗“╗∙ė┌öĄ(sh©┤)ō■(j©┤)ÄņĪóöĄ(sh©┤)ō■(j©┤)é}ÄņĄ─═┌Š“╝╝ąg(sh©┤)╝░▓óąą═┌Š“ęčĮø(j©®ng)║▄ļyĖ▀ą¦Ąž═Ļ│╔║Ż┴┐öĄ(sh©┤)ō■(j©┤)Ą─Ęų╬÷Ż╗Ųõ┤╬Ė▀░║Ą─▄øė▓╝■│╔▒Šę▓ūĶų╣┴╦įŲĢr(sh©¬)┤·öĄ(sh©┤)ō■(j©┤)═┌Š“ŽĄĮy(t©»ng)Ą─░l(f©Ī)š╣Ż╗ūŅ║¾é„Įy(t©»ng)Ą─¾wŽĄ╝▄śŗ(g©░u)▓╗─▄═Ļ│╔═┌Š“╦ŃĘ©─▄┴”Ą─╠ß╣®Ż¼╗∙▒Š╩Ūį┌ęįå╬éĆ(g©©)╦ŃĘ©×ķš¹¾w─ŻēKŻ¼ė├æ¶ų╗─▄╩╣ė├ęčėąĄ─╦ŃĘ©╗“ųžą┬ŠÄīæ╦ŃĘ©═Ļ│╔ūį╝║¬Ü(d©▓)╠žĄ─śI(y©©)äš(w©┤)ĪŻ
ĪĪĪĪįŲėŗ(j©¼)╦ŃįŲėŗ(j©¼)╦Ń╩Ūę╗ĘN╔╠śI(y©©)ėŗ(j©¼)╦Ń─Ż╩ĮŻ¼╦³īóėŗ(j©¼)╦Ń╚╬äš(w©┤)Ęų▓╝į┌┤¾┴┐ėŗ(j©¼)╦ŃÖC(j©®)śŗ(g©░u)│╔Ą─┘Yį┤│ž╔ŽŻ¼╩╣Ė„ĘNæ¬(y©®ng)ė├ŽĄĮy(t©»ng)─▄ē“Ė∙ō■(j©┤)ąĶę¬½@╚Īėŗ(j©¼)╦Ń┴”Īó┤µā”(ch©│)┐šķg║═ą┼ŽóĘ■äš(w©┤)ĪŻ═¼Ģr(sh©¬)įŲėŗ(j©¼)╦Ń╩Ū▓óąąėŗ(j©¼)╦ŃĪóĘų▓╝╩Įėŗ(j©¼)╦Ń║═ŠW(w©Żng)Ė±ėŗ(j©¼)╦ŃĄ─░l(f©Ī)š╣Ż¼╗“š▀šf╩Ū▀@ą®ėŗ(j©¼)╦Ń┐ŲīW(xu©”)Ė┼─ŅĄ─╔╠śI(y©©)īŹ(sh©¬)¼F(xi©żn)ĪŻ
ĪĪĪĪ═©│ŻšJ(r©©n)×ķįŲėŗ(j©¼)╦Ń░³└©ęįŽ┬3 éĆ(g©©)īė┤╬Ą─Ę■äš(w©┤)Ż║╗∙ĄA(ch©│)įO(sh©©)╩®╝┤Ę■äš(w©┤)Ż©IaaSŻ®ĪóŲĮ┼_(t©ói)╝┤Ę■äš(w©┤)Ż©PaaSŻ®ĪóSaaSŻ╗ŲõųąIaaS ╠ß╣®ęįė▓╝■įO(sh©©)éõ×ķ╗∙ĄA(ch©│)Ą─ėŗ(j©¼)╦ŃĪó┤µā”(ch©│)║═ŠW(w©Żng)Įj(lu©░)Ę■äš(w©┤)Ż¼īŹ(sh©¬)¼F(xi©żn)┴╦ī”ė▓╝■┘Yį┤Ą─│ķŽ¾▓óĘ■äš(w©┤)╗»╠ß╣®Ż¼╩╣Ą├Ęų▓╝╩Įėŗ(j©¼)╦Ń║═Ęų▓╝╩Į┤µā”(ch©│)│╔×ķ¼F(xi©żn)īŹ(sh©¬)ĪŻ
ĪĪĪĪįŲėŗ(j©¼)╦ŃŠ▀ėąę╗ą®╠ž³c(di©Żn)Ż║
ĪĪĪĪ(1)╠ōöM╗»ĪŻįŲėŗ(j©¼)╦Ńų¦│ųė├æ¶į┌╚╬ęŌ╬╗ų├╩╣ė├Ė„ĘNĮKČ╦ęį½@╚Īæ¬(y©®ng)ė├Ę■äš(w©┤)Ż¼╦∙šłŪ¾Ą─┘Yį┤üĒūįįŲČ°▓╗╩Ū╣╠Č©Ą─Īóėąą╬Ą─īŹ(sh©¬)¾wŻ¼▓óŪęī”ė┌ė├æ¶üĒšfų╗ąĶę¬╩╣ė├įŲ╠ß╣®Ą─Ę■äš(w©┤)╝┤┐╔ĪŻ
ĪĪĪĪ(2)═©ė├ąįĪŻįŲėŗ(j©¼)╦Ń▓╗ßśī”╠žČ©Ą─æ¬(y©®ng)ė├Ż¼Č°╩Ū┐╔ęįį┌įŲĄ─ų¦ō╬Ž┬śŗ(g©░u)įņ│÷Ū¦ūā?n©©i)f╗»Ą─æ¬(y©®ng)ė├Ż¼═¼ę╗éĆ(g©©)įŲ┐╔ęį═¼Ģr(sh©¬)ų¦ō╬▓╗═¼Ą─æ¬(y©®ng)ė├▀\(y©┤n)ąąĪŻ
ĪĪĪĪ(3)Ė▀┐╔öU(ku©░)š╣ąį╝░│¼┤¾ęÄ(gu©®)─ŻĪŻįŲĄ─ęÄ(gu©®)─Ż┐╔ęįäė(d©░ng)æB(t©żi)öU(ku©░)š╣Ż¼▓óŪę▀@ĘNäė(d©░ng)æB(t©żi)öU(ku©░)š╣ī”ė├æ¶╩Ū═Ė├„Ą─Ż¼▓óŪę▓╗ė░Ēæė├æ¶Ą─śI(y©©)äš(w©┤)║═æ¬(y©®ng)ė├ĪŻ═¼Ģr(sh©¬)▀@ĘNöU(ku©░)š╣╩Ū│¼┤¾ęÄ(gu©®)─ŻĄ─Ż¼╚ńGoogle įŲėŗ(j©¼)╦ŃęčĮø(j©®ng)ōĒėą╔Ž░┘╚f┼_(t©ói)Ę■äš(w©┤)Ų„Ż¼AmazonĪóIBMĪó╬ó▄øĄ╚ę▓ōĒėąÄū╩«╚f┼_(t©ói)Ę■äš(w©┤)Ų„ĪŻ
ĪĪĪĪ(4)┐╔┐┐ąįĖ▀ĪŻįŲėŗ(j©¼)╦Ń╩╣ė├ČÓĖ▒▒Š╚▌Õe(cu©░)ĪóČÓėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)═¼śŗ(g©░u)┐╔╗źōQĄ╚┤ļ╩®üĒ▒ŻšŽĘ■äš(w©┤)Ą─Ė▀┐╔┐┐ąįĪŻ
ĪĪĪĪ(5)Įø(j©®ng)Ø·(j©¼)ąį║├ĪŻįŲĄ─╠ž╩Ō╚▌Õe(cu©░)ÖC(j©®)ųŲī¦(d©Żo)ų┬┐╔ęį▓╔ė├┴«ār(ji©ż)Ą─╣Ø(ji©”)³c(di©Żn)üĒśŗ(g©░u)│╔įŲŻ¼Č°įŲĄ─ūįäė(d©░ng)╗»╝»ųą╩Į╣▄└Ē╩╣Ą├┤¾┴┐Ų¾śI(y©©)¤oąĶžō(f©┤)ō·(d©Īn)╚šęµĖ▀░║Ą─öĄ(sh©┤)ō■(j©┤)ųąą─╣▄└Ē│╔▒ŠĪŻįŲĄ─═©ė├ąį╩╣┘Yį┤Ą─└¹ė├┬╩▌^ų«é„Įy(t©»ng)ŽĄĮy(t©»ng)┤¾Ę∙╠ß╔²Ż¼ę“┤╦ė├æ¶┐╔ęį│õĘųŽĒ╩▄įŲĄ─Ą═│╔▒Šā×(y©Łu)ä▌ĪŻ
ĪĪĪĪ1.3 öĄ(sh©┤)ō■(j©┤)═┌Š“įŲ╗»▓▀┬į
ĪĪĪĪįŲėŗ(j©¼)╦ŃĄ─│÷¼F(xi©żn)╝┤ĮoöĄ(sh©┤)ō■(j©┤)═┌Š“ĦüĒ┴╦å¢Ņ}║═╠¶æ(zh©żn)Ż¼ę▓ĮoöĄ(sh©┤)ō■(j©┤)═┌Š“ĦüĒą┬Ą─ÖC(j©®)ė÷——öĄ(sh©┤)ō■(j©┤)═┌Š“╝╝ąg(sh©┤)īóĢ■(hu©¼)│÷¼F(xi©żn)╗∙ė┌įŲėŗ(j©¼)╦ŃĄ─ą┬─Ż╩ĮĪŻ╚ń║╬śŗ(g©░u)Į©╗∙ė┌įŲėŗ(j©¼)╦ŃĄ─öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)ę▓īó╩ŪśI(y©©)Įń├µ┼RĄ─ų„ę¬å¢Ņ}ų«ę╗Ż¼äō(chu©żng)Į©ę╗éĆ(g©©)ė├æ¶ģó┼cĪóķ_░l(f©Ī)╝╝ąg(sh©┤)ę¬Ū¾▓╗Ė▀Ą─Īó┐ņ╦┘Ēææ¬(y©®ng)Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)ę▓╩ŪŲ╚ŪąąĶę¬ĮŌøQĄ─å¢Ņ}ĪŻ
ĪĪĪĪÅ─śI(y©©)Įńī”įŲėŗ(j©¼)╦ŃĄ─└ĒĮŌüĒ┐┤Ż¼įŲėŗ(j©¼)╦Ńäė(d©░ng)æB(t©żi)Ą─Īó┐╔╔ņ┐sĄ─ėŗ(j©¼)╦Ń─▄┴”╩╣Ą├Ė▀ą¦Ą─║Ż┴┐öĄ(sh©┤)ō■(j©┤)═┌Š“│╔×ķ┐╔─▄ĪŻįŲėŗ(j©¼)╦ŃSaaS ╣”─▄Ą─└ĒĮŌ║═ś╦(bi©Īo)£╩(zh©│n)╗»Ż¼╩╣Ą├╗∙ė┌Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“SaaS ╗»ėą┴╦╝╝ąg(sh©┤)║═└ĒšōĄ─ų¦│ųŻ¼ę▓īó╩╣Ą├öĄ(sh©┤)ō■(j©┤)═┌Š“├µŽ“┤¾▒Ŗ╗»║═Ų¾śI(y©©)╗»ĪŻ╬─š┬ų„ę¬╩ŪÅ─╗∙ė┌įŲėŗ(j©¼)╦ŃŲĮ┼_(t©ói)Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“Ę■äš(w©┤)╗»Īó═┌Š“╦ŃĘ©▓óąą╗»Īó═┌Š“╦ŃĘ©ĮM╝■╗»ĮŪČ╚▀M(j©¼n)ąąśŗ(g©░u)Į©öĄ(sh©┤)ō■(j©┤)═┌Š“SaaS ŲĮ┼_(t©ói)Ż¼╚ńłD╦∙╩ŠĪŻ
ĪĪĪĪ╚ńłD1 ╦∙╩ŠŻ¼╬─š┬╠ß│÷Ą─╗∙ė┌įŲėŗ(j©¼)╦ŃĄ─öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)╝▄śŗ(g©░u)▓╔ė├ĘųīėĄ─╦╝ŽļŻ║╩ūŽ╚Ąūīėų¦ō╬▓╔ė├įŲėŗ(j©¼)╦ŃŲĮ┼_(t©ói)Ż¼▓ó╩╣ė├įŲėŗ(j©¼)╦ŃŲĮ┼_(t©ói)╠ß╣®Ą─Ęų▓╝┤µā”(ch©│)ęį╝░Ęų▓╝╩Įėŗ(j©¼)╦Ń─▄┴”═Ļ│╔öĄ(sh©┤)ō■(j©┤)═┌Š“ėŗ(j©¼)╦Ń─▄┴”Ą─▓óąąīŹ(sh©¬)¼F(xi©żn)Ż╗Ųõ┤╬öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)į┌įO(sh©©)ėŗ(j©¼)╔Ž▓╔ė├Ęų▓╝╩ĮĪó┐╔▓Õ░╬ĮM╝■╗»╦╝┬ĘŻ¼ų¦│ųČÓ╦ŃĘ©▓┐╩Īóš{(di©żo)Č╚Ą╚Ż╗ūŅ║¾öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)╠ß╣®Ą─╦ŃĘ©─▄┴”▓╔ė├Ę■äš(w©┤)Ą─ĘĮ╩Įī”═Ō▒®┬ČŻ¼▓óų¦│ų▓╗═¼śI(y©©)äš(w©┤)ŽĄĮy(t©»ng)Ą─š{(di©żo)ė├Ż¼Å─Č°▌^ĘĮ▒ŃĄžīŹ(sh©¬)¼F(xi©żn)śI(y©©)äš(w©┤)ŽĄĮy(t©»ng)Ą─═Ų╦]Īó═┌Š“Ą╚ŽÓĻP(gu©Īn)╣”─▄ąĶŪ¾ĪŻ

łD1 ╗∙ė┌įŲėŗ(j©¼)╦ŃĄ─öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)┐é¾w╝▄śŗ(g©░u)łD
2.öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)įŲ╝▄śŗ(g©░u)
įŲėŗ(j©¼)╦ŃĄ─Ęų▓╝╩Į┤µā”(ch©│)║═Ęų▓╝╩Įėŗ(j©¼)╦Ń┤┘╩╣┴╦ą┬ę╗┤·öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)Ą─ūāĖ’ĪŻłD2 ╩Ū╗∙ė┌įŲĄ─öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)╝▄śŗ(g©░u)ĪŻ┐╝æ]ĄĮ═┌Š“╦ŃĘ©║══Ų╦]╦ŃĘ©Ą─▓óąą╗»║═Ęų▓╝╗»╩Ūę╗éĆ(g©©)īŻķTĄ─Īó┤¾Ą─šnŅ}Ż¼ę“┤╦╬─š┬Ģ║▓╗░³║¼Š▀¾w╦ŃĘ©Ą─▓óąą╗»║═įŲ╗»Ą─ā╚(n©©i)╚▌ĪŻ
╚ńłD2 ╦∙╩ŠŻ¼įōŲĮ┼_(t©ói)╩Ū╗∙ė┌įŲėŗ(j©¼)╦ŃŲĮ┼_(t©ói)īŹ(sh©¬)¼F(xi©żn)Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“įŲĘ■äš(w©┤)ŲĮ┼_(t©ói)Ż¼▓╔ė├ĘųīėįO(sh©©)ėŗ(j©¼)Ą─╦╝Žļęį╝░├µŽ“ĮM╝■Ą─įO(sh©©)ėŗ(j©¼)╦╝┬ĘŻ¼┐é¾w╔ŽĘų×ķ3 īėŻ¼ūįŽ┬Ž“╔Žę└┤╬×ķŻ║įŲėŗ(j©¼)╦Ńų¦ō╬ŲĮ┼_(t©ói)īėĪóöĄ(sh©┤)ō■(j©┤)═┌Š“─▄┴”īėĪóöĄ(sh©┤)ō■(j©┤)═┌Š“įŲĘ■äš(w©┤)īėĪŻ

łD2 ╗∙ė┌įŲėŗ(j©¼)╦ŃĄ─öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)╝▄śŗ(g©░u)
ĪĪĪĪįŲėŗ(j©¼)╦Ńų¦ō╬ŲĮ┼_(t©ói)īė
ĪĪĪĪįŲėŗ(j©¼)╦Ńų¦ō╬ŲĮ┼_(t©ói)īėų„ę¬╩Ū╠ß╣®Ęų▓╝╩Į╬─╝■┤µā”(ch©│)ĪóöĄ(sh©┤)ō■(j©┤)Äņ┤µā”(ch©│)ęį╝░ėŗ(j©¼)╦Ń─▄┴”ĪŻųą┼d═©ėŹėąūįų„čą░l(f©Ī)Ą─įŲėŗ(j©¼)╦ŃŲĮ┼_(t©ói)Ż¼įō╝▄śŗ(g©░u)┐╔ęį╗∙ė┌Ų¾śI(y©©)ūįų„čą░l(f©Ī)Ą─įŲėŗ(j©¼)╦ŃŲĮ┼_(t©ói)Ż¼ę▓┐╔ęį╗∙ė┌Ą┌╚²ĘĮ╠ß╣®Ą─įŲėŗ(j©¼)╦ŃŲĮ┼_(t©ói)ĪŻ
ĪĪĪĪöĄ(sh©┤)ō■(j©┤)═┌Š“─▄┴”īė
ĪĪĪĪöĄ(sh©┤)ō■(j©┤)═┌Š“─▄┴”īėų„ę¬╩Ū╠ß╣®═┌Š“Ą─╗∙ĄA(ch©│)─▄┴”Ż¼░³║¼╦ŃĘ©Ę■äš(w©┤)╣▄└ĒĪóš{(di©żo)Č╚ę²ŲĪóöĄ(sh©┤)ō■(j©┤)▓óąą╠Ä└Ē┐“╝▄Ż¼▓ó╠ß╣®ī”öĄ(sh©┤)ō■(j©┤)═┌Š“įŲĘ■äš(w©┤)īėĄ──▄┴”ų¦ō╬ĪŻįōīė┐╔ęįų¦│ųĄ┌╚²ĘĮ═┌Š“╦ŃĘ©╣żŠ▀Ą─Įė╚ļŻ¼└²╚ńWekaĪóMathout Ą╚Ęų▓╝╩Į╦ŃĘ©ÄņŻ¼═¼Ģr(sh©¬)ę▓┐╔ęį╠ß╣®ā╚(n©©i)▓┐Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“╦ŃĘ©║══Ų╦]╦ŃĘ©ÄņĪŻ
ĪĪĪĪöĄ(sh©┤)ō■(j©┤)═┌Š“įŲĘ■äš(w©┤)īė
ĪĪĪĪįŲĘ■äš(w©┤)īėų„ę¬╩Ūī”═Ō╠ß╣®öĄ(sh©┤)ō■(j©┤)═┌Š“įŲĘ■äš(w©┤)Ż¼Ę■äš(w©┤)─▄┴”ĘŌčbĄ─Įė┐┌ą╬╩Į┐╔ęį╩ŪČÓśėĄ─Ż¼░³└©╗∙ė┌║åå╬ī”Ž¾įLå¢ģf(xi©”)ūh(SOAP) Ą─WebserviceĪóĪóHTTPĪóXML ╗“▒ŠĄžæ¬(y©®ng)ė├│╠ą“ŠÄ│╠Įė┐┌(API) Ą╚ČÓĘNą╬╩ĮĪŻįŲĘ■äš(w©┤)īėę▓┐╔ęįų¦│ų╗∙ė┌ĮY(ji©”)śŗ(g©░u)╗»▓ķįāšZčįšZŠõĄ─įLå¢Ż¼▓ó╠ß╣®ĮŌ╬÷ę²ŪµŻ¼ęįūįäė(d©░ng)š{(di©żo)ė├įŲĘ■äš(w©┤)ĪŻĖ„éĆ(g©©)śI(y©©)äš(w©┤)ŽĄĮy(t©»ng)┐╔ęįĖ∙ō■(j©┤)öĄ(sh©┤)ō■(j©┤)║═śI(y©©)äš(w©┤)Ą─ąĶ꬚{(di©żo)ė├ĪóĮMčböĄ(sh©┤)ō■(j©┤)═┌Š“įŲĘ■äš(w©┤)ĪŻ
ĪĪĪĪ╬─š┬╠ß│÷Ą─╗∙ė┌įŲėŗ(j©¼)╦ŃĄ─öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)┼cé„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“ŽĄĮy(t©»ng)╝▄śŗ(g©░u)ŽÓ▒╚ėąĖ▀┐╔öU(ku©░)š╣ąįĪó║Ż┴┐öĄ(sh©┤)ō■(j©┤)╠Ä└Ē─▄┴”Īó├µŽ“Ę■äš(w©┤)Īóė▓╝■│╔▒ŠĄ═┴«Ą╚ā×(y©Łu)įĮąįŻ¼┐╔ęįų¦│ų┤¾ĘČć·Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)═┌Š“Ą─įO(sh©©)ėŗ(j©¼)║═æ¬(y©®ng)ė├ĪŻ
ĪĪĪĪ3.╗∙ė┌įŲėŗ(j©¼)╦ŃöĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)Ą─ĻP(gu©Īn)µI╝╝ąg(sh©┤)
ĪĪĪĪ3.1 įŲėŗ(j©¼)╦Ń╝╝ąg(sh©┤)
ĪĪĪĪĘų▓╝╩Įėŗ(j©¼)╦Ń╩ŪĮŌøQ║Ż┴┐öĄ(sh©┤)ō■(j©┤)═┌Š“╚╬äš(w©┤)Ż¼╠ßĖ▀║Ż┴┐öĄ(sh©┤)ō■(j©┤)═┌Š“Ą─ėąą¦╩ųČ╬ų«ę╗Ż¼į┌└Ēšō║═īŹ(sh©¬)█`╔ŽęčĮø(j©®ng)½@Ą├ūCīŹ(sh©¬)ĪŻĘų▓╝╩Įėŗ(j©¼)╦Ń░³║¼┴╦Ęų▓╝╩Į┤µā”(ch©│)║═▓óąąėŗ(j©¼)╦Ńā╔éĆ(g©©)īė├µĄ─ā╚(n©©i)╚▌Ż¼Č°įŲėŗ(j©¼)╦ŃŲĮ┼_(t©ói)╠ß╣®┴╦Ęų▓╝╩Į╬─╝■┤µā”(ch©│)║═▓󹹥─ėŗ(j©¼)╦Ń─▄┴”Ż¼ę“┤╦║▄║├ĄžĮŌøQ┴╦▀@ā╔éĆ(g©©)īė├µĄ─ā╚(n©©i)╚▌ĪŻŽ┬├µų„ę¬Ęų╬÷ÄūéĆ(g©©)ų„┴„Ą─Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)║═Ęų▓╝╩Į▓óąąėŗ(j©¼)╦Ń┐“╝▄Ż¼ęįĖ³║├Ąžśŗ(g©░u)Į©įŲėŗ(j©¼)╦ŃöĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)Ą─║╦ą─ų¦ō╬─▄┴”ĪŻ
ĪĪĪĪĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)ėąą¦ĄžĮŌøQ┴╦║Ż┴┐öĄ(sh©┤)ō■(j©┤)┤µā”(ch©│)å¢Ņ}Ż¼▓óīŹ(sh©¬)¼F(xi©żn)┴╦╬╗ų├═Ė├„ĪóęŲäė(d©░ng)═Ė├„Īóąį─▄═Ė├„ĪóöU(ku©░)š╣═Ė├„ĪóĖ▀╚▌Õe(cu©░)ĪóĖ▀░▓╚½ĪóĖ▀ąį─▄Ą╚ĻP(gu©Īn)µI╣”─▄ĪŻ─┐Ū░śI(y©©)Įń▒╚▌^┴„ąąĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)ėąGoogle ╬─╝■ŽĄĮy(t©»ng)(GFS)ĪóĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)(HDFS)Īó╬─╝■ŽĄĮy(t©»ng)(KFS)Ż¼▀@3 ĘNĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Č╝╩Ū╗∙ė┌Goolgle ╠ß│÷Ą─Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)└Ēšō▀M(j©¼n)ąąčą░l(f©Ī)Ą─ĪŻGoogle╠ß│÷Ą─GFS Š═╩ŪĮŌøQŲõ║Ż┴┐öĄ(sh©┤)ō■(j©┤)┤µā”(ch©│)║═╦č╦„ĪóĘų╬÷Ą╚å¢Ņ}Ż¼Č°║═KFS ╩Ū╗∙ė┌GFS └Ēšō╗∙ĄA(ch©│)╔ŽīŹ(sh©¬)¼F(xi©żn)Ą─ķ_į┤ŽĄĮy(t©»ng)Ż¼▓óŪęį┌╔╠śI(y©©)║═īW(xu©”)ąg(sh©┤)ŅI(l©½ng)ė“Ą├ĄĮ┴╦ÅVĘ║Ą─æ¬(y©®ng)ė├ĪŻ
ĪĪĪĪĘų▓╝╩Į▓óąąėŗ(j©¼)╦Ń┐“╝▄ī”ė┌Ė▀ą¦═Ļ│╔öĄ(sh©┤)ō■(j©┤)═┌Š“ėŗ(j©¼)╦Ń╚╬äš(w©┤)śOŲõųžę¬Ż¼▓óŪę╦³ī”Ęų▓╝╩Įėŗ(j©¼)╦ŃĄ─ę╗ą®╝╝ąg(sh©┤)╝Ü(x©¼)╣Ø(ji©”)▀M(j©¼n)ąą┴╦ĘŌčbŻ¼└²╚ńöĄ(sh©┤)ō■(j©┤)Ęų▓╝Īó╚╬äš(w©┤)▓óąąĪó╚╬äš(w©┤)š{(di©żo)Č╚Īóžō(f©┤)▌dŲĮ║ŌĪó╚╬äš(w©┤)╚▌Õe(cu©░)ĪóŽĄĮy(t©»ng)╚▌Õe(cu©░)Ą╚Ż¼╩╣ė├æ¶▓╗ąĶę¬┐╝æ]▀@ą®╝Ü(x©¼)╣Ø(ji©”)Ż¼Č°ų╗ę¬┐╝æ]╚╬äš(w©┤)ķgĄ─▀ē▌ŗĻP(gu©Īn)ŽĄĪŻ▀@śė▓╗āH┐╔ęį╠ßĖ▀čą░l(f©Ī)Ą─ą¦┬╩Ż¼▀Ć┐╔ęįĮĄĄ═ŽĄĮy(t©»ng)ŠSūo(h©┤)Ą─│╔▒ŠĪŻ─┐Ū░Ąõą═Ą─Ęų▓╝╩Įėŗ(j©¼)╦Ń┐“╝▄ėąŻ║
ĪĪĪĪMapReduce ╩Ū╠ß│÷Ą─ę╗éĆ(g©©)▓óąąėŗ(j©¼)╦Ń┐“╝▄Ż¼╦³┐╔ęįį┌┤¾┴┐PC ÖC(j©®)╔Ž▓óąął╠(zh©¬)ąą║Ż┴┐öĄ(sh©┤)ō■(j©┤)Ą─╩š╝»║═Ęų╬÷╚╬äš(w©┤)ĪŻ╦³░č╚ń║╬▀M(j©¼n)ąą╚╬äš(w©┤)▓óąął╠(zh©¬)ąąĪó╚ń║╬▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)Ęų▓╝Īó╚ń║╬╚▌Õe(cu©░)ĪóŠW(w©Żng)Įj(lu©░)ĦīÆĢr(sh©¬)čėĄ╚å¢Ņ}Ą─ĮŌøQĘĮ░ĖŠÄ┤aŻ¼▓óĘŌčbį┌┴╦ę╗éĆ(g©©)Äņ└’├µŻ¼╩╣ė├æ¶ų╗ąĶꬳ╠(zh©¬)ąąöĄ(sh©┤)ō■(j©┤)▀\(y©┤n)╦Ń╝┤┐╔Ż¼Č°▓╗▒žĻP(gu©Īn)ą─▓óąąėŗ(j©¼)╦ŃĪó╚▌Õe(cu©░)ĪóöĄ(sh©┤)ō■(j©┤)Ęų▓╝Īóžō(f©┤)▌dŠ∙║ŌĄ╚Å═(f©┤)ļsĄ─╝Ü(x©¼)╣Ø(ji©”)ĪŻ═¼Ģr(sh©¬)╦³ėųī”╔Žīėæ¬(y©®ng)ė├╠ß╣®┴╝║├║åå╬Ą─│ķŽ¾Įė┐┌ĪŻMapReduce ų„ę¬æ¬(y©®ng)ė├į┌╦č╦„ĪóöĄ(sh©┤)ō■(j©┤)é}ÄņĪóöĄ(sh©┤)ō■(j©┤)═┌Š“ŅI(l©½ng)ė“ĪŻ
ĪĪĪĪPregel ╩ŪGoogle ╠ß│÷Ą─Ą³┤·╠Ä└Ēėŗ(j©¼)╦Ń┐“╝▄Ż¼╦³Š▀ėąĖ▀ą¦Īó┐╔öU(ku©░)š╣║═╚▌Õe(cu©░)Ą─╠žąįŻ¼▓óļ[▓ž┴╦Ęų▓╝╩ĮŽÓĻP(gu©Īn)Ą─╝Ü(x©¼)╣Ø(ji©”)Ż¼š╣¼F(xi©żn)Įo╚╦éāĄ─āHāH╩Ūę╗éĆ(g©©)▒Ē¼F(xi©żn)┴”║▄ÅŖ(qi©óng)Īó║▄╚▌ęūŠÄ│╠Ą─┤¾ą═łD╦ŃĘ©╠Ä└ĒĄ─ėŗ(j©¼)╦Ń┐“╝▄ĪŻPregel Ą─ų„ę¬æ¬(y©®ng)ė├ł÷Š░╩Ū┤¾ą═Ą─łDėŗ(j©¼)╦ŃŻ¼└²╚ńĮ╗═©ŠĆ┬ĘĪó╝▓▓Ī▒¼░l(f©Ī)┬ĘÅĮĪóWEB ╦č╦„Ą╚ŽÓĻP(gu©Īn)ŅI(l©½ng)ė“ĪŻ
ĪĪĪĪDryad ╩Ū╬ó▄ø╣Ķ╣╚蹊┐į║äō(chu©żng)Į©Ą─蹊┐ĒŚ(xi©żng)─┐Ż¼ų„ę¬ė├üĒ╠ß╣®ę╗éĆ(g©©)╗∙ė┌windows ▓┘ū„ŽĄĮy(t©»ng)Ą─Ęų▓╝╩Įėŗ(j©¼)╦ŃŲĮ┼_(t©ói)Ż¼┐é¾wė├üĒų¦│ųėąŽ“¤oŁh(hu©ón)łDŅÉ ą═öĄ(sh©┤)ō■(j©┤)┴„Ą─▓óąą│╠ą“ĪŻ╬ó▄øė┌─Ļą¹▓╝Ż¼═Żų╣ī”Dryad ▀M(j©¼n)ąą░µ▒Š╔²╝ēŻ¼▐D(zhu©Żn)═ČHadoop ╝┤MapReduce ėŗ(j©¼)╦Ń┐“╝▄ĪŻ
ĪĪĪĪ─┐Ū░śI(y©©)Įńķ_į┤Ą─įŲėŗ(j©¼)╦ŃŲĮ┼_(t©ói)Ż¼ ░³║¼HDFS ║═MapReduceŻ¼×ķ║Ż┴┐öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)╠ß╣®═ĻéõĄ─įŲėŗ(j©¼)╦ŃŲĮ┼_(t©ói)ų¦ō╬ŲĮ┼_(t©ói)ĪŻ
ĪĪĪĪ3.2 öĄ(sh©┤)ō■(j©┤)ģR╝»š{(di©żo)Č╚ųąą─
ĪĪĪĪöĄ(sh©┤)ō■(j©┤)ģR╝»š{(di©żo)Č╚ųąą─īŹ(sh©¬)¼F(xi©żn)ī”Įė╚ļ▒ŠŲĮ┼_(t©ói)Ą─śI(y©©)äš(w©┤)öĄ(sh©┤)ō■(j©┤)Ą─ģR╝»Ż¼┐╔ęįĮŌøQ▓╗═¼öĄ(sh©┤)ō■(j©┤)Ą─ęÄ(gu©®)╝så¢Ņ}Ż¼▓óų¦│ųĖ„ĘN▓╗═¼Ą─į┤öĄ(sh©┤)ō■(j©┤)Ė±╩ĮĪŻį┤öĄ(sh©┤)ō■(j©┤)Ė±╩Įų¦│ų┬ō(li©ón)ÖC(j©®)╩┬äš(w©┤)╠Ä└ĒŽĄĮy(t©»ng)(OLTP)öĄ(sh©┤)ō■(j©┤)Īó┬ō(li©ón)ÖC(j©®)Ęų╬÷╠Ä└ĒŽĄĮy(t©»ng)(OLAP)öĄ(sh©┤)ō■(j©┤)ĪóĖ„ĘN╚šųŠöĄ(sh©┤)ō■(j©┤)Īó┼└ŽxöĄ(sh©┤)ō■(j©┤)Ą╚Ż¼═¼Ģr(sh©¬)ę¬╠ß╣®ČÓĘNöĄ(sh©┤)ō■(j©┤)═¼▓ĮĘĮ╩ĮŻ¼└²╚ńöĄ(sh©┤)ō■(j©┤)ÄņīŹ(sh©¬)Ģr(sh©¬)═¼▓ĮĪósocket Ž¹Žó═¼▓ĮĪó╬─╝■é„▌öģf(xi©”)ūh═¼▓ĮĄ╚Ė„ĘNĖ„śėĄ─ĘĮ╩ĮŻ¼╚ńłD3╦∙╩ŠĪŻ
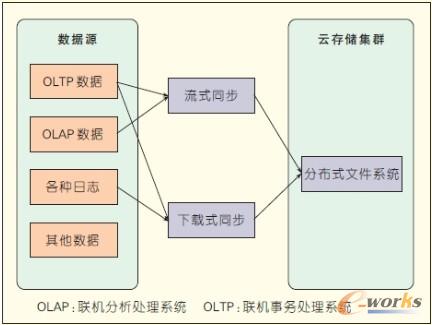
łD3 öĄ(sh©┤)ō■(j©┤)ģR╝»ųąą─
ĪĪĪĪöĄ(sh©┤)ō■(j©┤)ģR╝»š{(di©żo)Č╚ųąą─ų„ę¬╩Ū═Ļ│╔ī”▓╗═¼ŅÉą═öĄ(sh©┤)ō■(j©┤)Ą─ģR╝»ĪŻ▒ŠöĄ(sh©┤)ō■(j©┤)ģR╝»š{(di©żo)Č╚ųąą─▓╔ė├─Ż░Õ╗»įO(sh©©)ėŗ(j©¼)╝╝ąg(sh©┤)Ż¼ų¦│ųą┬öĄ(sh©┤)ō■(j©┤)Ą──Ż░Õ║═į¬öĄ(sh©┤)ō■(j©┤)┼õų├ęį▀_(d©ó)ĄĮ▓╗═¼śI(y©©)äš(w©┤)öĄ(sh©┤)ō■(j©┤)Ą─Įy(t©»ng)ę╗╩š╝»║═ęÄ(gu©®)╝sĪŻ
ĪĪĪĪ3.3 Ę■äš(w©┤)š{(di©żo)Č╚║═Ę■äš(w©┤)╣▄└Ē╝╝ąg(sh©┤)
ĪĪĪĪ×ķ┴╦─▄ē“ūī▓╗═¼Ą─śI(y©©)äš(w©┤)ŽĄĮy(t©»ng)╩╣ė├▒Šėŗ(j©¼)╦ŃŲĮ┼_(t©ói)Ż¼ŲĮ┼_(t©ói)▒žĒÜę¬╠ß╣®Ę■äš(w©┤)š{(di©żo)Č╚║═Ę■äš(w©┤)╣▄└Ē╣”─▄ĪŻĘ■äš(w©┤)š{(di©żo)Č╚Ė∙ō■(j©┤)Ę■äš(w©┤)Ą─ā×(y©Łu)Ž╚╝ēęį╝░Ę■äš(w©┤)║═┘Yį┤Ą─Ųź┼õŪķørĄ╚▀M(j©¼n)ąąš{(di©żo)Č╚Ż¼ĮŌøQĘ■äš(w©┤)Ą─▓óąą╗ź│ŌĪóĖ¶ļxĄ╚Ż¼▒ŻūCöĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)Ą─įŲĘ■äš(w©┤)╩Ū░▓╚½Īó┐╔┐┐Ą─Ż¼▓óĖ∙ō■(j©┤)Ę■äš(w©┤)╣▄┐ž▀M(j©¼n)ąąš{(di©żo)Č╚┐žųŲĪŻ
ĪĪĪĪĘ■äš(w©┤)╣▄└ĒīŹ(sh©¬)¼F(xi©żn)Įy(t©»ng)ę╗Ą─Ę■äš(w©┤)ūóāįĪóĘ■äš(w©┤)▒®┬ČĄ╚╣”─▄Ż¼▓╗āHų¦│ų▒ŠĄžĘ■äš(w©┤)─▄┴”Ą─▒®┬ČŻ¼ę▓ų¦│ųĄ┌╚²ĘĮöĄ(sh©┤)ō■(j©┤)═┌Š“─▄┴”Ą─Įė╚ļŻ¼║▄║├Ąž?c©ói)U(ku©░)š╣öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)Ą─Ę■äš(w©┤)─▄┴”ĪŻ
ĪĪĪĪ3.4 ═┌Š“╦ŃĘ©▓óąą╗»╝╝ąg(sh©┤)
ĪĪĪĪ═┌Š“╦ŃĘ©▓óąą╗»╩Ūėąą¦└¹ė├įŲėŗ(j©¼)╦ŃŲĮ┼_(t©ói)╠ß╣®Ą─╗∙ĄA(ch©│)─▄┴”Ą─ĻP(gu©Īn)µI╝╝ąg(sh©┤)ų«ę╗Ż¼╔µ╝░ĄĮ╦ŃĘ©╩Ūʱ┐╔ęį▓óąąĪóęį╝░▓óąą▓▀┬įĄ─▀xō±Ą╚╝╝ąg(sh©┤)ĪŻ╬─š┬═©▀^K-means Š█ŅÉ╦ŃĘ©▓óąą╗»▓óąąėŗ(j©¼)╦Ń┐“╝▄üĒšf├„═┌Š“╦ŃĘ©Ą─▓óąą╗»╝╝ąg(sh©┤)[13]ĪŻ
ĪĪĪĪ3.4.1 K-means ╦ŃĘ©Ą─ų„ę¬╦╝Žļ
ĪĪĪĪK-means╦ŃĘ©Ą─ų„ę¬╦╝Žļ╩Ū╗∙ė┌╩╣Š█ŅÉąį─▄ųĖś╦(bi©Īo)ūŅąĪ╗»ĪŻ▀@└’╦∙ė├Ą─Š█ŅÉ£╩(zh©│n)ät║»öĄ(sh©┤)╩ŪŠ█ŅÉ╝»ųą├┐ę╗śė▒Š³c(di©Żn)ĄĮįōŅÉ┤žųąą─³c(di©Żn)ŠÓļxŲĮĘĮų«║═Ż¼▓ó╩╣╦³ūŅąĪ╗»ĪŻ╚ńłD4 ╦∙╩ŠŻ¼K Š∙ųĄ╦ŃĘ©Ą─╠Ä└Ē┴„│╠╚ńŽ┬Ż║╩ūŽ╚Ż¼ļSÖC(j©®)Ąž▀xō±k éĆ(g©©)ī”Ž¾Ż¼├┐éĆ(g©©)ī”Ž¾┤·▒Ēę╗éĆ(g©©)┤žĄ─│§╩╝Š∙ųĄ║═ųąą─Ż╗ī”╩ŻėÓĄ─├┐éĆ(g©©)ī”Ž¾Ż¼ätĖ∙ō■(j©┤)Ųõ┼cĖ„éĆ(g©©)┤žĄ─Š∙ųĄŠÓļxŻ¼īó╦³ųĖ┼╔ĄĮūŅŽÓ╦ŲĄ─┤žŻ╗╚╗║¾ėŗ(j©¼)╦Ń├┐éĆ(g©©)┤žĄ─ą┬Š∙ųĄĪŻ▀@éĆ(g©©)▀^│╠▓╗öÓųžÅ═(f©┤)Ż¼ų▒ĄĮ£╩(zh©│n)ät║»öĄ(sh©┤)╩šö┐ĪŻ═©│ŻŻ¼▓╔ė├ŲĮĘĮš`▓Ņ£╩(zh©│n)ätŻ¼ŲõČ©┴x╚ńłD(1)╦∙╩ŠŻ║

łDŻ©1Ż®K-means╦ŃĘ©
ĪĪĪĪŲõųąŻ¼E ╩ŪöĄ(sh©┤)ō■(j©┤)╝»ųą╦∙ėąī”Ž¾Ą─ŲĮĘĮš`▓Ņ║═Ż¼p ╩Ū┐šķgųąĄ─³c(di©Żn)Ż¼▒Ē╩ŠĮoČ©Ą─ī”Ž¾Ż¼mi ╩Ū┤žCi Ą─Š∙ųĄĪŻī”ė┌├┐éĆ(g©©)┤žųąĄ─├┐éĆ(g©©)ī”Ž¾Ż¼╩ūŽ╚ę¬Ū¾│÷ī”Ž¾ĄĮŲõ┤žųąą─Ą─Š∙ųĄĄ─ŲĮĘĮŻ¼╚╗║¾į┘Ū¾║═ĪŻ
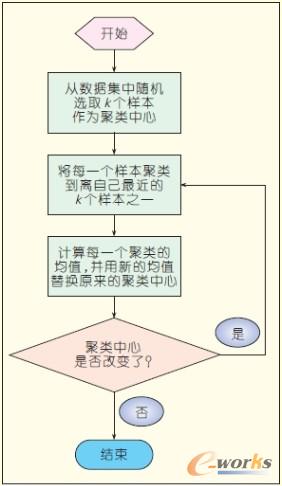
łD4 K-means╦ŃĘ©┴„│╠łD
ĪĪĪĪ3.4.2 K-means ▓óąą╗»╦╝┬Ę
ĪĪĪĪ╩ŪęįŠ█ŅÉųąą─üĒäØĘųŠ█ŅÉĄ─Ż¼ę╗Ą®k éĆ(g©©)Š█ŅÉųąą─┤_Č©┴╦Ż¼Š█ŅÉ┐╔┴ó╝┤═Ļ│╔ĪŻę“┤╦Ż¼▀@└’ų„ę¬ųv╩÷╚ń║╬▓óąąīŹ(sh©¬)¼F(xi©żn)Ė³ą┬Š█ŅÉųąą─ĪŻ
ĪĪĪĪį┌ļSÖC(j©®)Ą─│§╩╝╗»k éĆ(g©©)Š█ŅÉųąą─ęį║¾Ż¼├┐ę╗┤╬╚╬äš(w©┤)Ą─ł╠(zh©¬)ąąČ╝Ģ■(hu©¼)Ė³ą┬«ö(d©Īng)Ū░éĆ(g©©)Š█ŅÉųąą─Ą─ųĄĪŻį┌ė│╔õļAČ╬Ż¼ī”ė┌├┐ę╗éĆ(g©©)śė▒ŠOS Ż¼ąĶę¬ėŗ(j©¼)╦Ń┼cŲõūŅĮ³Ą─Š█ŅÉųąą─Oi (0≤i ≤k -1) Ż¼╚╗║¾▌ö│÷<iŻ¼OS >µIųĄī”ĪŻ
ĪĪĪĪį┌╗»║å(Reducer) ļAČ╬Ż¼┐“╝▄Ģ■(hu©¼)╩š╝»ī┘ė┌ŽÓ═¼µIĄ─ųĄŻ¼ŽÓ«ö(d©Īng)ė┌ī”├┐éĆ(g©©)Š█ŅÉųąą─Oi (0≤i ≤k-1) Ż¼Č°ļx╦³ūŅĮ³Ą─śė▒ŠČ╝Ģ■(hu©¼)ū„×ķųĄ╩š╝»ŲüĒĪŻ▀@śėReducer └’Š═┐╔ęį└¹ė├▀@ą®śė▒Šųžą┬╣└ėŗ(j©¼)│÷k éĆ(g©©)Š█ŅÉųąą─Ż¼╚ńłDŻ©2Ż®╦∙╩ŠŻ║

łDŻ©2Ż®K-means ▓óąą╗»╦╝┬Ę
ĪĪĪĪ▀@śėŻ¼į┌ę╗▌åMapReduce ═Ļ│╔║¾Ż¼ą┬Ą─Š█ŅÉųąą─ę▓ęčĮø(j©®ng)ėŗ(j©¼)╦Ń│÷üĒĪŻ═©▀^▒╚▌^▒Š▌åŠ█ŅÉųąą─┼c╔Žę╗▌åŠ█ŅÉųąą─▓Ņ«ÉČ╚Ż¼┐╔┤_Č©╦ŃĘ©╩Ūʱ╩šö┐ĪŻ
ĪĪĪĪ4.ĮY(ji©”)╩°šZ
ĪĪĪĪ╬─š┬═©▀^ī”öĄ(sh©┤)ō■(j©┤)═┌Š“║═įŲėŗ(j©¼)╦Ń╝╝ąg(sh©┤)Ą─░l(f©Ī)š╣Ęų╬÷Ż¼╠ß│÷┴╦╗∙ė┌įŲėŗ(j©¼)╦ŃĄ─öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)╝▄śŗ(g©░u)ęį╝░öĄ(sh©┤)ō■(j©┤)═┌Š“Ę■äš(w©┤)╗»Ą─╦╝┬ĘĪŻ▒ŠŲĮ┼_(t©ói)▓╗āHāH╩Ū╗∙ė┌įŲėŗ(j©¼)╦ŃīŹ(sh©¬)¼F(xi©żn)┴╦ę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)Ż¼═¼Ģr(sh©¬)ę▓ī”öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)▀M(j©¼n)ąą┴╦╗»ĪŻ▒ŠŲĮ┼_(t©ói)┐╔ęį×ķ▀\(y©┤n)ĀI╔╠ĪóŲ¾śI(y©©)╠ß╣®ą¦ęµį÷ųĄĄ─öĄ(sh©┤)ō■(j©┤)═┌Š“æ¬(y©®ng)ė├Ż¼═¼Ģr(sh©¬)ę▓£p╔┘┴╦▀\(y©┤n)ĀI╔╠ĪóŲ¾śI(y©©)į┌öĄ(sh©┤)ō■(j©┤)═┌Š“╝╝ąg(sh©┤)╔ŽĄ─═Č╚ļĪŻ▀\(y©┤n)ĀI╔╠ĪóŲ¾śI(y©©)╝┤┐╔ęįäō(chu©żng)Į©ūį╝║ā╚(n©©i)▓┐Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“╦ĮėąįŲŻ¼×ķā╚(n©©i)▓┐«a(ch©Żn)ŲĘ╠ß╣®öĄ(sh©┤)ō■(j©┤)═┌Š“Ę■äš(w©┤)Ż¼ę▓┐╔ęį╠ß╣®öĄ(sh©┤)ō■(j©┤)═┌Š“╣½ė├įŲŻ¼×ķ▓╗═¼Ą─Ų¾śI(y©©)╠ß╣®öĄ(sh©┤)ō■(j©┤)═┌Š“Ę■äš(w©┤)ĪŻ
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_(t©ói)╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N(y©┤n)║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://www.lukmueng.com/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║╗∙ė┌įŲėŗ(j©¼)╦ŃĄ─öĄ(sh©┤)ō■(j©┤)═┌Š“ŲĮ┼_(t©ói)╝▄śŗ(g©░u)╝░ŲõĻP(gu©Īn)µI╝╝ąg(sh©┤)蹊┐
▒Š╬─ŠW(w©Żng)ųĘŻ║http://www.lukmueng.com/html/support/11121511700.html



▀xą═ųąą─")
¾w“×(y©żn)ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")