ĪĪĪĪ“┤¾öĄō■”į┌╗ź┬ōŠWąąśIųąęč╩ŪŲš▒ķ¼FŽ¾Ż¼ę╗╝ę╣½╦Š├┐╠ņ└█ĘeĄ─ė├æ¶ąą×ķöĄō■╔§ų┴ęč▓╗─▄ė├TBüĒ║Ō┴┐ĪŻ║Ż┴┐öĄō■ī”īŹĢrĘų╬÷║═ėŗ╦Ń╠ß│÷┴╦Ė³Ė▀Ą─ę¬Ū¾Ż¼īŹĢr╠Ä└Ē│╠ą“▒žĒÜ┤_▒Żį┌ć└Ė±Ą─Ģrķgā╚Ēææ¬Ż¼═©│Żęį├ļ×ķå╬╬╗Ż¼╔§ų┴╩Ū║┴├ļĪŻé„ĮyĄ─┼·┴┐ėŗ╦Ń─Żą═ęč¤oĘ©ØMūŃ▀@ą®ę¬Ū¾Ż¼▒žĒÜė├īŻķTĄ─īŹĢrėŗ╦ŃŽĄĮy╠µ┤·ĪŻ«öŪ░Ż¼śIĮńų¬├¹Ą─īŹĢrėŗ╦ŃŽĄĮyėąGoogleĄ─MillWheelĪóTwitterķ_į┤Ą─StormĪóSpark StreamingĄ╚ĪŻ
ĪĪĪĪ░┘Č╚ūįų„čą░l┴╦ć°ā╚ęÄ─ŻūŅ┤¾Ą─īŹĢrėŗ╦ŃŲĮ┼_——Dstream║═TMĪŻ╦³éāĖ„ėąŪ¦Ū’Ż¼▀mė├ė┌▓╗═¼Ą─śIäšł÷Š░ĪŻDstreamų╝į┌├µŽ“ėąŽ“¤oŁhĄ─öĄō■╠Ä└Ē┴„Ż¼ØMūŃĖ▀Ģrą¦ąįę¬Ū¾Ą─ėŗ╦ŃśIäšł÷Š░Ż©╚ńīŹĢrCTRėŗ╦ŃŻ®Ż¼┐╔▀_ĄĮ║┴├ļ╝ēĄ─Ēææ¬ĪŻTMät╩Ūqueue-worker─Ż╩ĮĄ─£╩īŹĢrworkflowėŗ╦ŃŽĄĮyŻ¼┐╔ØMūŃ├ļ╝ēĄĮĘųńŖ╝ēĒææ¬Ż¼▓óŠ▀éõtransactionšZ┴xŻ¼┴„╚ļŲĮ┼_Ą─öĄō■╝┤╩╣į┌ŲĮ┼_░l╔·╣╩šŽĄ─ŪķørŽ┬Ż¼ę▓─▄ū÷ĄĮ▓╗ųž▓╗üGĪŻ▀@ę╗ŽĄĮyų„ę¬æ¬ė├ė┌Ą═ĢrčėĪóĖ▀═╠═┬╝░ī”öĄō■═Ļš¹ąįę¬Ū¾śOĖ▀Ą─ł÷Š░Ż¼╚ńł¾▒Ē╔·│╔ŽĄĮyĪóėŗ┘M┴„ėŗ╦ŃĄ╚ĪŻ
ĪĪĪĪ░┘Č╚īŹĢrėŗ╦ŃŲĮ┼_ĮķĮB
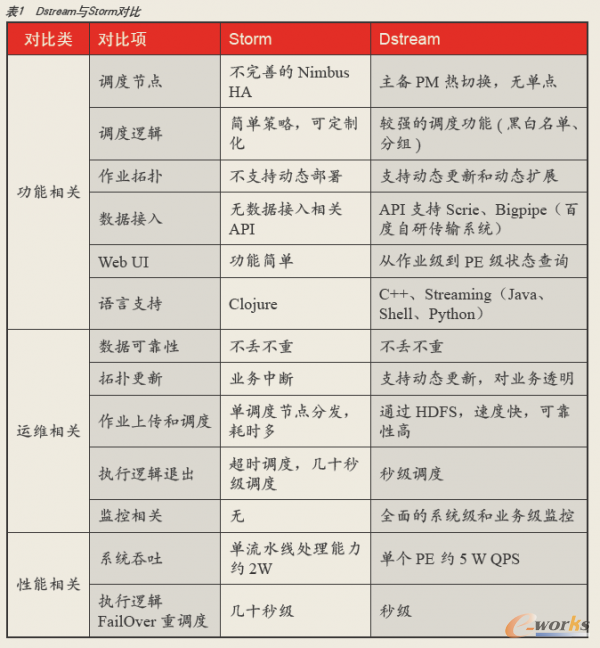
ĪĪĪĪDstream┴óĒŚų«│§Ż¼śIĮń▀Ćø]ėąŅÉ╦ŲĄ─ķ_į┤ŽĄĮyŻ©Storm╔ą╬┤š²╩Į═Ų│÷Ż®Ż¼ų╗─▄ę└┐┐čą░lłFĻĀūį╝║├■╦„ĪŻ─┐Ū░DstreamŲĮ┼_Ą─╝»╚║ęÄ─Żęč│¼Ū¦┼_Ż¼å╬╝»╚║ūŅ┤¾╠Ä└ĒöĄō■┴┐│¼▀^50TB/╠ņŻ¼╝»╚║ĘÕųĄQPS 193W/SŻ¼ŽĄĮyĘĆČ©ąįĪóėŗ╦Ń─▄┴”ęč═Ļ╚½ØMūŃ║Ż┴┐öĄō■Ģrą¦ąį╠Ä└ĒąĶŪ¾ĪŻ╝┤╩╣┼cStormŽÓ▒╚Ż¼Dstreamį┌ŽĄĮy│╔╩ņČ╚Īóąį─▄ĪóĘĆČ©ąįĄ╚ĘĮ├µ╚į╚╗ā×ä▌├„’@Ż¼Š▀¾wī”▒╚öĄō■╚ń▒Ē1╦∙╩ŠĪŻ
▒Ē 1 Dstream┼cStormī”▒╚
ĪĪĪĪTMŲĮ┼_Å─2013─Ļķ_╩╝čą░lŻ¼─┐Ū░╝»╚║ęÄ─Ż×ķ░┘┼_╝ēŻ¼å╬╝»╚║ūŅ┤¾╠Ä└ĒöĄō■┴┐│¼▀^30TB/╠ņŻ¼ūŅ┤¾QPS 20W/SĪŻ╗∙ė┌TMŲĮ┼_īŹ¼FĄ─ČÓ┬ĘöĄō■┴„╩ĮjoinĮŌøQĘĮ░ĖŻ¼ęčŠ▀éõ│¼┤¾Ģrķg┤░┴„╩Įjoinėŗ╦Ń─▄┴”Ż¼Ģrķg┤░┐╔ĄĮ“╠ņ”╝ēäeŻ¼▒ŻūCöĄō■▓╗üG▓╗ųžŻ¼▀_ĄĮ┴╦śIĮńŽ╚▀M╦«ŲĮŻ¼▓óęčæ¬ė├ė┌░┘Č╚ČÓŚlśI䚊ƥ─³cō¶╚šųŠĪóš╣¼F╚šųŠĄ─joinėŗ╦ŃĪŻ
ĪĪĪĪį┌TMŲĮ┼_╔ŽŻ¼ė├æ¶śŗįņę╗éĆū„śI├Ķ╩÷╬─╝■üĒĻU╩÷Ė„ĘNworkerų«ķgĄ─öĄō■┴„Ž“ĻPŽĄ║═├┐éĆworker╦∙ąĶĄ─┘Yį┤Ż¼═©▀^clientīóū„śI╠ßĮ╗ĮoTMŲĮ┼_Ż¼╚╗║¾ė╔TMš{Č╚▓ó▀\ąąĪŻTMŲĮ┼_┐╔└¹ė├╣½╦Š┐šķeĘ■äšŲ„┘Yį┤▀Mąąėŗ╦ŃĪŻŽĄĮyŠ▀ėąęįŽ┬ÄūéĆ╠žąįĪŻ
ĪĪĪĪ▒ŻūCöĄō■═Ļš¹║═Ģrą¦ĪŻöĄō■į┌╠Ä└Ē▀^│╠ųąŻ¼▒ŻūC▓╗Ģ■│÷¼FųžÅ═║═üG╩¦Ż¼į┌▒ŻūCjoin▒╚└²Ą─ŪķørŽ┬Ż¼ūŅČ╠Ģrķgā╚▌ö│÷ĮoŽ┬ė╬╩╣ė├ĪŻ
ĪĪĪĪ╚▌╚╠öĄō■┴„Ą─ķLĢrķg┐ńČ╚ĪŻ▓╗Ž▐ųŲ▌ö╚ļöĄō■┴„Ą─Ģrķgčė▀t║═┐ńČ╚Ż¼═©▀^ę²╚ļ┐╔┐┐┤µā”ŽĄĮyüĒ“┤µā”ę╗ĘNöĄō■┴„Ż¼ŲõėÓöĄō■┴„▓ķįā”Ą─ĘĮ╩ĮŻ¼ĮŌøQķLĢrķg┐ńČ╚Ž┬öĄō■joinå¢Ņ}Ż╗ī”ė┌Ģrķg┐ńČ╚ąĪĄ─öĄō■┴„Ż¼╠ß╣®╗∙ė┌╗¼äė┤░┐┌Ą─ā╚┤µjoinĘĮ╩ĮĪŻ
ĪĪĪĪ═©ė├ąįĪŻ┐╔ęį═¼Ģræ¬ī”▓╗═¼Ģrķg┐ńČ╚Ą─joinŻ¼ę╗░Ńæ¬ė├╝╚ąĶę¬Ģrą¦ąį▌^Ė▀Ż¼ėųę¬Ū¾öĄō■join▒╚└²▓╗═¼Ż¼Ģrą¦ąįę▓ėą╦∙▓╗═¼ĪŻ═©▀^ę²╚ļČÓ╝ēųžįćjoinÖCųŲŻ¼ŽĄĮy═¼ĢrØMūŃ┴╦▀@ā╔éĆąĶŪ¾ĪŻ
ĪĪĪĪĖ▀┐╔┐┐ąį║═Ė▀┐╔▀\ŠSĪŻ═©▀^ų¦│ųČÓ╝»╚║éõĘ▌ĪóČÓÖCĘ┐éõĘ▌Ą╚ĘĮ░ĖŻ¼▒ŻūCŽĄĮyĄ─Ė▀┐╔┐┐ąįĪŻ┴Ē═Ō═©▀^TMŲĮ┼_╣▄└Ēæ¬ė├═žōõĪó╝»╚║┼õų├Ż¼ų¦│ų┼õų├äėæBĖ³ą┬Īó╣╩šŽūįäėÖz£yĄ╚Ż¼į÷ÅŖŽĄĮyĄ─Ė▀┐╔▀\ŠSąįĪŻ
ĪĪĪĪīŹĢrėŗ╦ŃŲĮ┼_æ¬ė├░Ė└²
ĪĪĪĪ╚šųŠīŹĢrETL
ĪĪĪĪ░┘Č╚ā╚▓┐ėąĮyę╗Ą─ė├æ¶öĄō■é}ÄņŻ¼öĄō■╚ļÄņĄ─ĘĮ╩Įėąā╔ĘNŻ║ę╗╩Ū═©▀^╗∙ė┌HadoopĄ─ETLŲĮ┼_┼·┴┐Č©Ų┌╚ļÄņŻ¼Č■╩Ūų▒Įė═©▀^īŹĢrėŗ╦ŃŽĄĮyīŹĢr╚ļÄņĪŻŲõųąīŹĢr╚ļÄņŽĄĮy├¹×ķUDW–RTŻ¼╦³╗∙ė┌ĄūīėīŹĢrėŗ╦ŃŲĮ┼_Č■┤╬ķ_░lŻ¼ų┬┴”ė┌×ķ░┘Č╚╠ß╣®ę╗éĆ├µŽ“┴„Ą─ĪóīŹĢrĄ─öĄō■ETLŲĮ┼_Ż╗═©▀^įOėŗ║═īŹ¼Fę╗éĆŅÉSQLĪó┐╔öUš╣Ą─┴„▀\╦ŃŽĄĮyŻ¼UDW–RTŽĄĮy─▄×ķīŹĢröĄō■╠Ä└Ē╠ß╣®╗∙ĄAįO╩®║═öĄō■╣®ĮoĪŻ
ĪĪĪĪUDW-RTŽĄĮy▀ē▌ŗ╔Ž┐╔Ęų×ķęįŽ┬╚²īėŻ©╚ńłD1Ż®ĪŻ
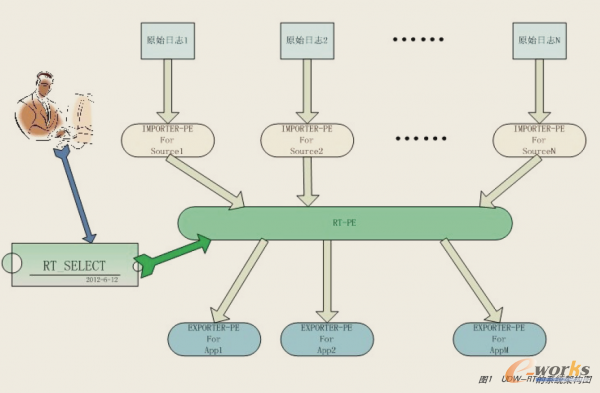
łD 1 UDW-RTŽĄĮy╝▄śŗłD
ĪĪĪĪĄ┌ę╗īė×ķRT-importerŻ¼Ųõ┬Üž¤╩ŪŪÕŽ┤ĪóÜw▓óĪóĮYśŗ╗»Å─pipeŽĄĮyī¦╚ļĄ─öĄō■▓óė│╔õ│╔┴„Ż¼├┐éĆ┴„┐╔ęį▒╗ŽļŽ¾│╔╩Ūę╗éƤoŽ▐ķLĄ─öĄō■▒ĒĪŻ
ĪĪĪĪĄ┌Č■īė╩ŪRT-PEŻ¼žōž¤ł╠ąą┴„╦ŃūėĪŻ═©▀^æ¬ė├┴„ŅÉSQL╦ŃūėŻ©─┐Ū░ų╗ų¦│ų▓┐ĘųSQL▓┘ū„Ż¼╚ńunionĪófiltering║═projectionĄ╚Ż®Ż¼┐╔ęį╔·│╔ę╗éĆ╗“ČÓéĆ▀ē▌ŗ┴„Ż╗├┐éĆ▀ē▌ŗ┴„Č╝┐╔▒╗Ž┬ė╬┴ŃéĆ╗“ČÓéĆöĄō■╩╣ė├ĘĮėåķåĪŻ
ĪĪĪĪĄ┌╚²īė╩ŪRTŽĄĮyĄ─æ¬ė├│╠ą“Ż¼▒╗ĘQ×ķRT-EXPORTERŻ╗öĄō■╩╣ė├ĘĮ═©▀^Æņ▌dRT-EXPORTERüĒ▀MąąöĄō■Ž¹┘MĪŻ
ĪĪĪĪīŹĢrĖéārRTB
ĪĪĪĪTMŲĮ┼_ī”RTBīŹĢrĖéār«a╔·Ą─ā╔┬Ę╚šųŠ▀Mąąjoinėŗ╦ŃŻ¼ęį┤_Č©Ėéār│╔╣”Ą─ÅVĖµŻ¼ėŗ╦Ń║¾Ą─▌ö│÷öĄō■│╔×ķ░┘Č╚Ę┤ū„▒ūĪóCTRėŗ╦ŃĪóėŗ┘MĄ╚ČÓéĆ║¾Č╦ŽĄĮyĄ─╚ļ┐┌ĪŻTM┴„╩Įjoin╝▄śŗų¦ō╬┴╦RTBĖéār─Ż╩Į┬õĄžŻ¼ØMūŃ┴╦ÅVĖµų„ī”ė┌ā╚╚▌═ČĘ┼╠ß│÷Ą─Ė³Š½£╩ĪóīŹĢr║═│╠ą“╗»Ą─ę¬Ū¾ĪŻ═¼ĢrŻ¼═©▀^TMŲĮ┼_Ż¼░┘Č╚ŠW├╦śIäšīŹ¼F┴╦Ū░║¾Č╦╝▄śŗĮŌ±ŅŻ¼╠ß╔²┴╦ŽĄĮyĮĪēčąį║═┐╔öUš╣ąįŻ¼╦³ė╔ęįŽ┬ÄūéĆų„ę¬▓┐ĘųĮM│╔Ż©╚ńłD2╦∙╩ŠŻ®ĪŻ
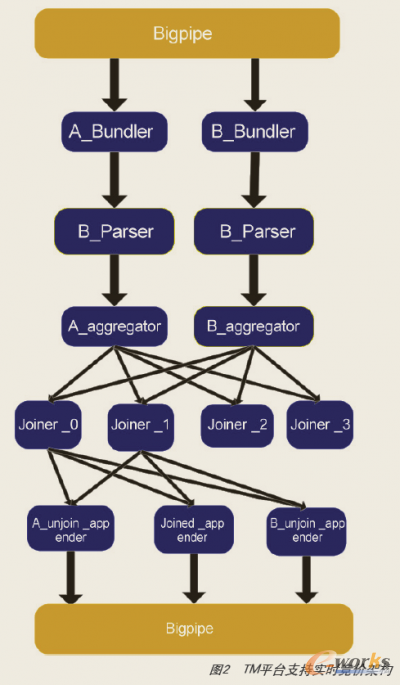
łD 2 TMŲĮ┼_ų¦│ųīŹĢrĖéār╝▄śŗ
ĪĪĪĪBigpipeŻ║░┘Č╚ā╚▓┐Ęų▓╝╩ĮŽ¹Žó░l╦═ėåķåŽĄĮyŻ¼čė▀tĄ═Ż¼▓óŪę─▄▒ŻūCöĄō■į┌é„▌ö▀^│╠ųą▓╗ųž▓╗üGĪŻ
ĪĪĪĪBundlerŻ║TMŲĮ┼_ėåķåBigpipeöĄō■Ą─═©ė├─ŻēKŻ¼A_bundler║═B_bundler▒Ē╩Šėåķå▓╗═¼Ą─öĄō■┴„ĪŻ
ĪĪĪĪParserŻ║öĄō■ĮŌ╬÷─ŻēKŻ¼ų„ę¬īó─┐Ū░öĄō■Ė±╩ĮÅ─╬─▒Š▐D╗»│╔PBĪŻ
ĪĪĪĪAggregatorŻ║╬─╝■Š█║Ž─ŻēKŻ¼ų„ę¬╩ŪīóParser«a╔·Ą─ąĪ╬─╝■Š█║Ž│╔┤¾╬─╝■Ż¼£p╔┘╬─╝■éĆöĄĪŻ
ĪĪĪĪJoinerŻ║║╦ą──ŻēKŻ¼žōž¤ā╔ĘNöĄō■┴„Ą─joinĪŻ▓╔ė├╗∙ė┌╗¼äė┤░┐┌Ą─ĘĮ╩ĮŻ¼▒ŻūCöĄō■┴„Ą─┴„äė║═čė▀tŻ¼═¼ĢröĄō■į┌┤░┐┌ā╚▓┐ėąą“Ż¼╩╣Ą├å╬éĆjoinerį┌▌ö│÷öĄō■Ģrėąą“ĪŻ┴Ē═Ō═©▀^aggregator┴„┐ž▓▀┬įŻ¼┐╔ęį▒ŻūCĖ„éĆjoiner▌ö│÷öĄō■Ģrķg┤┴ŽÓ▓Ņ▓╗┤¾Ż¼Å─Č°▒ŻūCš¹¾wöĄō■▌ö│÷üyą“ėąŽ▐ĪŻ
ĪĪĪĪAppenderŻ║TMŲĮ┼_Ž“Bigpipe░l▓╝öĄō■Ą──ŻēKĪŻ▀@└’Ęų┴╦╚²┬ĘŻ¼Ęųäe▒Ē╩ŠAĪóBā╔ĘNöĄō■┴„ø]ėąjoin╔ŽĄ─ĮY╣¹Ż¼ęį╝░join╔ŽĄ─ĮY╣¹ĪŻ
ĪĪĪĪ┐éĮY
ĪĪĪĪ╗∙ė┌īŹĢrėŗ╦ŃŲĮ┼_Ż¼░┘Č╚ęčŠ▀éõČÓĘNĖ▀Ģrą¦ąįĄ─öĄō■╠Ä└ĒĮŌøQĘĮ░ĖŻ¼▀@ą®╝╝ągęčį┌įĮüĒįĮČÓĄ─æ¬ė├ł÷Š░ųą░lō]│÷ųžę¬ū„ė├ĪŻ╬┤üĒŻ¼░┘Č╚īó└^└m═Č╚ļŻ¼╔Ņ╗»ī”┤¾öĄō■īŹĢrėŗ╦Ń╝▄śŗ╝░ŲõĻPµI╝╝ągĄ─蹊┐Ż¼▀Mę╗▓Į═Ųäė┤¾öĄō■īŹĢrėŗ╦Ń└ĒšōĪóĘĮĘ©Īó╝╝ąg┼cŽĄĮyĄ─æ¬ė├┼c░lš╣Ż¼ęįØMūŃĖ³ÅVĘ║Ą─╩ął÷ąĶŪ¾║═æ¬ė├Ū░Š░ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.lukmueng.com/
▒Š╬─ś╦Ņ}Ż║░┘Č╚īŹĢrėŗ╦ŃŲĮ┼_Ą─īŹ¼F║═æ¬ė├
▒Š╬─ŠWųĘŻ║http://www.lukmueng.com/html/support/11121517192.html