1.ę²čį
ĪĪĪĪ«öĮ±Ż¼╔ńĢ■ą┼Žó╗»║═ŠWĮj╗»Ą─░lš╣ī¦ų┬öĄō■▒¼š©╩Įį÷ķLĪŻō■ĮyėŗŻ¼ŲĮŠ∙├┐├ļėą200╚fė├æ¶į┌╩╣ė├╣╚ĖĶ╦č╦„Ż¼Facebookė├æ¶├┐╠ņ╣▓ŽĒĄ─¢|╬„│¼▀^40ā|Ż¼Twitter├┐╠ņ╠Ä└ĒĄ─═Ų╠žöĄ┴┐│¼▀^3.4ā|ĪŻ═¼ĢrŻ¼┐ŲīWėŗ╦ŃĪóßt»¤ąl╔·ĪóĮ╚┌Īó┴Ń╩█śIĄ╚Ė„ąąśIę▓ėą┤¾┴┐öĄō■į┌▓╗öÓ«a╔·ĪŻ2012─Ļ╚½Ū“ą┼Žó┐é┴┐ęčĮø▀_ĄĮ2.7 ZBŻ¼Č°ĄĮ2015─Ļ▀@ę╗öĄųĄŅAėŗĢ■▀_ĄĮ8 ZBĪŻ▀@ę╗¼FŽ¾ę²░l┴╦╚╦éāĄ─ÅVĘ║ĻPūóĪŻį┌īWągĮńŻ¼łDņ`¬ä½@Ą├š▀Jim Gray╠ß│÷┴╦┐ŲīW蹊┐Ą─Ą┌╦─ĘČ╩ĮŻ¼╝┤ęį┤¾öĄō■×ķ╗∙ĄAĄ─öĄō■├▄╝»ą═┐ŲīW蹊┐Ż╗2008─ĻĪČNature))═Ų│÷┴╦┤¾öĄō■īŻ┐»ī”Ųõš╣ķ_╠ĮėæŻ╗2011─ĻĪČScienceĪĘę▓═Ų│÷ŅÉ╦ŲĄ─öĄō■╠Ä└ĒīŻ┐»ĪŻIT«aśIĮńąąäėĖ³×ķĘeśOŻ¼│ų└mĻPūóöĄō■į┘└¹ė├Ż¼═┌Š“┤¾öĄō■Ą─Øōį┌ārųĄĪŻ─┐Ū░Ż¼┤¾öĄō■ęč│╔×ķ└^įŲėŗ╦Ńų«║¾ą┼Žó╝╝ągŅIė“Ą─┴Ēę╗éĆą┼Žó«aśIį÷ķL³cĪŻō■GartnerŅA£yŻ¼2013─Ļ┤¾öĄō■īóĦäė╚½Ū“ITų¦│÷340ā|├└į¬Ż¼ĄĮ2016─Ļ╚½Ū“į┌┤¾öĄō■ĘĮ├µĄ─┐é╗©┘Mīó▀_ĄĮ2320ā|├└į¬ĪŻGartnerīó“┤¾öĄō■”╝╝ąg┴ą╚ļ2012─Ļī”▒ŖČÓ╣½╦Š║═ĮM┐ŚÖCśŗŠ▀ėąæ┬įęŌ┴xĄ─╩«┤¾╝╝ąg┼c┌ģä▌ų«ę╗ĪŻ▓╗āH╚ń┤╦Ż¼ū„×ķć°╝ę║═╔ńĢ■Ą─ų„ę¬╣▄└Ēš▀Ż¼Ė„ć°š■Ė«ę▓╩Ū┤¾öĄō■╝╝ąg═ŲÅVĄ─ų„ę¬═Ųäėš▀ĪŻ2009─Ļ3į┬├└ć°š■Ė«╔ŽŠĆ┴╦data.govŠWšŠŻ¼Ž“╣½▒Ŗķ_Ę┼š■Ė«╦∙ōĒėąĄ─╣½╣▓öĄō■ĪŻļS║¾Ż¼ėóć°Īó░─┤¾└¹üåĄ╚š■Ė«ę▓ķ_╩╝┴╦┤¾öĄō■ķ_Ę┼Ą─▀M│╠Ż¼Įžų┴─┐Ū░Ż¼╚½╩└ĮńęčĮøš²╩Įėą35éĆć°╝ę║═Ąžģ^śŗĮ©┴╦ūį╝║Ą─öĄō■ķ_Ę┼ķT涊WšŠĪŻ├└ć°š■Ė«┬ō║Ž6éĆ▓┐ķTą¹▓╝┴╦2ā|├└į¬Ą─“┤¾öĄō■蹊┐┼c░lš╣ėŗäØ”ĪŻį┌╬ęć°Ż¼2012─Ļųąć°═©ą┼īWĢ■Īóųąć°ėŗ╦ŃÖCīWĢ■Ą╚ųžę¬īWągĮM┐ŚŽ╚║¾│╔┴ó┴╦┤¾öĄō■īŻ╝ę╬»åTĢ■Ż¼×ķ╬ęć°┤¾öĄō■æ¬ė├║═░lš╣╠ß╣®īWągū╔įāĪŻ
ĪĪĪĪ─┐Ū░┤¾öĄō■Ą─░lš╣╚į╚╗├µ┼Rų°įSČÓå¢Ņ}Ż¼░▓╚½┼cļ[╦Įå¢Ņ}╩Ū╚╦éā╣½šJĄ─ĻPµIå¢Ņ}ų«ę╗ĪŻ«öŪ░Ż¼╚╦éāį┌╗ź┬ōŠW╔ŽĄ─ę╗čįę╗ąąČ╝šŲ╬šį┌╗ź┬ōŠW╔╠╝ę╩ųųąŻ¼░³└©┘Å╬’┴ĢæTĪó║├ėč┬ōĮjŪķørĪóķåūx┴ĢæTĪóÖz╦„┴ĢæTĄ╚Ą╚ĪŻČÓĒŚīŹļH░Ė└²šf├„Ż¼╝┤╩╣¤o║”Ą─öĄō■▒╗┤¾┴┐╩š╝»║¾Ż¼ę▓Ģ■▒®┬ČéĆ╚╦ļ[╦ĮĪŻ╩┬īŹ╔ŽŻ¼┤¾öĄō■░▓╚½║¼┴xĖ³×ķÅVĘ║Ż¼╚╦éā├µ┼RĄ─═■├{▓ó▓╗āHŽ▐ė┌éĆ╚╦ļ[╦Įą╣┬®ĪŻ┼cŲõ╦³ą┼Žóę╗śėŻ¼┤¾öĄō■į┌┤µā”Īó╠Ä└ĒĪóé„▌öĄ╚▀^│╠ųą├µ┼RųTČÓ░▓╚½’LļUŻ¼Š▀ėąöĄō■░▓╚½┼cļ[╦Į▒ŻūoąĶŪ¾ĪŻČ°īŹ¼F┤¾öĄō■░▓╚½┼cļ[╦Į▒ŻūoŻ¼▌^ęį═∙Ųõ╦³░▓╚½å¢Ņ}(╚ńįŲėŗ╦ŃųąĄ─öĄō■░▓╚½Ą╚)Ė³×ķ╝¼╩ųĪŻ▀@╩Ūę“×ķį┌įŲėŗ╦ŃųąŻ¼ļm╚╗Ę■äš╠ß╣®╔╠┐žųŲ┴╦öĄō■Ą─┤µā”┼c▀\ąąŁhŠ│Ż¼Ą½╩Ūė├æ¶╚į╚╗ėąą®▐kĘ©▒Żūoūį╝║Ą─öĄō■Ż¼└²╚ń═©▀^├▄┤aīWĄ─╝╝ąg╩ųČ╬īŹ¼FöĄō■░▓╚½┤µā”┼c░▓╚½ėŗ╦ŃŻ¼╗“š▀═©▀^┐╔ą┼ėŗ╦ŃĘĮ╩ĮīŹ¼F▀\ąąŁhŠ│░▓╚½Ą╚ĪŻČ°į┌┤¾öĄō■Ą─▒│Š░Ž┬Ż¼FacebookĄ╚╔╠╝ę╝╚╩ŪöĄō■Ą─╔·«aš▀Ż¼ėų╩ŪöĄō■Ą─┤µā”Īó╣▄└Ēš▀║═╩╣ė├š▀Ż¼ę“┤╦Ż¼å╬╝ā═©▀^╝╝ąg╩ųČ╬Ž▐ųŲ╔╠╝ęī”ė├æ¶ą┼ŽóĄ─╩╣ė├Ż¼īŹ¼Fė├æ¶ļ[╦Į▒Żūo╩ŪśOŲõ└¦ļyĄ─╩┬ĪŻ
ĪĪĪĪ«öŪ░║▄ČÓĮM┐ŚČ╝šJūRĄĮ┤¾öĄō■Ą─░▓╚½å¢Ņ}Ż¼▓óĘeśOąąäėŲüĒĻPūó┤¾öĄō■░▓╚½å¢Ņ}ĪŻ2012─ĻįŲ░▓╚½┬ō├╦CSAĮMĮ©┴╦┤¾öĄō■╣żū„ĮMŻ¼ų╝į┌īżšęßśī”öĄō■ųąą─░▓╚½║═ļ[╦Įå¢Ņ}Ą─ĮŌøQĘĮ░ĖĪŻ▒Š╬─į┌╩ß└Ē┤¾öĄō■蹊┐¼FĀŅĄ─╗∙ĄA╔ŽŻ¼ųž³cĘų╬÷┴╦«öŪ░┤¾öĄō■╦∙ĦüĒĄ─░▓╚½╠¶æŻ¼įö╝ÜĻU╩÷┴╦«öŪ░┤¾öĄō■░▓╚½┼cļ[╦Į▒ŻūoĄ─ĻPµI╝╝ągĪŻąĶę¬ųĖ│÷Ą─╩ŪŻ¼┤¾öĄō■į┌ę²╚╦ą┬Ą─░▓╚½å¢Ņ}║═╠¶æĄ─═¼ĢrŻ¼ę▓×ķą┼Žó░▓╚½ŅIė“ĦüĒ┴╦ą┬Ą─░lš╣Ų§ÖCŻ¼╝┤╗∙ė┌┤¾öĄō■Ą─ą┼Žó░▓╚½ŽÓĻP╝╝ąg┐╔ęįĘ┤▀^üĒė├ė┌┤¾öĄō■Ą─░▓╚½║═ļ[╦Į▒ŻūoĪŻ▒Š╬─į┌Ą┌5╣Øī”Ųõ▀Mąą┴╦│§▓ĮĘų╬÷┼c╠ĮėæĪŻ
ĪĪĪĪ2.┤¾öĄō■蹊┐Ė┼╩÷
ĪĪĪĪ2.1 ┤¾öĄō■üĒį┤┼c╠žš„
ĪĪĪĪŲš▒ķĄ─ė^³cšJ×ķŻ¼┤¾öĄō■╩ŪųĖęÄ─Ż┤¾ŪęÅ═ļsĪóęįų┴ė┌║▄ļyė├¼FėąöĄō■Äņ╣▄└Ē╣żŠ▀╗“öĄō■╠Ä└Ēæ¬ė├üĒ╠Ä└ĒĄ─öĄō■╝»ĪŻ┤¾öĄō■Ą─│ŻęŖ╠ž³c░³└©┤¾ęÄ─Ż(volume)ĪóĖ▀╦┘ąį(velocity)║═ČÓśėąį(variety)ĪŻĖ∙ō■üĒį┤Ą─▓╗═¼Ż¼┤¾öĄō■┤¾ų┬┐╔Ęų×ķ╚ńŽ┬ÄūŅÉŻ║
ĪĪĪĪ(1)üĒūįė┌╚╦ĪŻ╚╦éāį┌╗ź┬ōŠW╗Ņäėęį╝░╩╣ė├ęŲäė╗ź┬ōŠW▀^│╠ųą╦∙«a╔·Ą─Ė„ŅÉöĄō■Ż¼░³└©╬─ūųĪółDŲ¼ĪóęĢŅlĄ╚ą┼ŽóŻ╗
ĪĪĪĪ(2)üĒūįė┌ÖCĪŻĖ„ŅÉėŗ╦ŃÖCą┼ŽóŽĄĮy«a╔·Ą─öĄō■Ż¼ęį╬─╝■ĪóöĄō■ÄņĪóČÓ├Į¾wĄ╚ą╬╩Į┤µį┌Ż¼ę▓░³└©īÅėŗĪó╚šųŠĄ╚ūįäė╔·│╔Ą─ą┼ŽóŻ╗
ĪĪĪĪ(3)üĒūįė┌╬’ĪŻĖ„ŅÉöĄūųįOéõ╦∙▓╔╝»Ą─öĄō■ĪŻ╚ńözŽ±Ņ^«a╔·Ą─öĄūųą┼╠¢Īóßt»¤╬’┬ōŠWųą«a╔·Ą─╚╦Ą─Ė„ĒŚ╠žš„ųĄĪó╠ņ╬─═¹▀hńR╦∙«a╔·Ą─┤¾┴┐öĄō■Ą╚ĪŻ
ĪĪĪĪ2.2 ┤¾öĄō■Ęų╬÷─┐ś╦
ĪĪĪĪ─┐Ū░┤¾öĄō■Ęų╬÷æ¬ė├ė┌┐ŲīWĪóßt╦ÄĪó╔╠śIĄ╚Ė„éĆŅIė“Ż¼ė├═Š▓Ņ«ÉŠ▐┤¾ĪŻĄ½Ųõ─┐ś╦┐╔ęįÜw╝{×ķ╚ńŽ┬ÄūŅÉŻ║
ĪĪĪĪ(1)½@Ą├ų¬ūR┼c═Ų£y┌ģä▌
ĪĪĪĪ╚╦éā▀MąąöĄō■Ęų╬÷ė╔üĒęčŠ├Ż¼ūŅ│§ŪęūŅųžę¬Ą──┐Ą─Š═╩Ū½@Ą├ų¬ūRĪó└¹ė├ų¬ūRĪŻė╔ė┌┤¾öĄō■░³║¼┤¾┴┐įŁ╩╝ĪóšµīŹą┼ŽóŻ¼┤¾öĄō■Ęų╬÷─▄ē“ėąą¦Ąž▐ŚēéĆ¾w▓Ņ«ÉŻ¼Ä═ų·╚╦éā═Ė▀^¼FŽ¾ĪóĖ³£╩┤_Ąž░č╬š╩┬╬’▒│║¾Ą─ęÄ┬╔ĪŻ╗∙ė┌═┌Š“│÷Ą─ų¬ūRŻ¼┐╔ęįĖ³£╩┤_Ąžī”ūį╚╗╗“╔ńĢ■¼FŽ¾▀MąąŅA£yĪŻĄõą═Ą─░Ė└²╩ŪGoogle╣½╦ŠĄ─Google Flu TrendsŠWšŠĪŻ╦³═©▀^Įyėŗ╚╦éāī”┴„Ėąą┼ŽóĄ─╦č╦„Ż¼▓ķįāGoogleĘ■äšŲ„╚šųŠĄ─IPĄžųĘ┼ąČ©╦č╦„üĒį┤Ż¼Å─Č°░l▓╝ī”╩└ĮńĖ„Ąž┴„ĖąŪķørĄ─ŅA£yĪŻėų╚ńŻ¼╚╦éā┐╔ęįĖ∙ō■Twitterą┼ŽóŅA£y╣╔Ų▒ąąŪķĄ╚ĪŻ
ĪĪĪĪ(2)Ęų╬÷šŲ╬šéĆąį╗»╠žš„
ĪĪĪĪéĆ¾w╗Ņäėį┌ØMūŃ─│ą®╚║¾w╠žš„Ą─═¼ĢrŻ¼ę▓Š▀ėą§r├„Ą─éĆąį╗»╠žš„ĪŻš²╚ń“ķL╬▓└Ēšō”ųą─ŪŚl╝ÜķLĄ─╬▓░═─ŪśėŻ¼▀@ą®╠žš„┐╔─▄Ū¦▓Ņ╚fäeĪŻŲ¾śI═©▀^ķLĢrķgĪóČÓŠSČ╚Ą─öĄō■Ęe└█Ż¼┐╔ęįĘų╬÷ė├æ¶ąą×ķęÄ┬╔Ż¼Ė³£╩┤_Ąž├Ķ└LŲõéĆ¾w▌å└¬Ż¼×ķė├æ¶╠ß╣®Ė³║├Ą─éĆąį╗»«aŲĘ║═Ę■䚯¼ęį╝░Ė³£╩┤_Ą─ÅVĖµ═Ų╦]ĪŻ└²╚ńGoogle═©▀^Ųõ┤¾öĄō■«aŲĘī”ė├æ¶Ą─┴ĢæT║═É█║├▀MąąĘų╬÷Ż¼Ä═ų·ÅVĖµ╔╠įu╣└ÅVĖµ╗Ņäėą¦┬╩Ż¼ŅA╣└į┌╬┤üĒ┐╔─▄┤µį┌Ė▀▀_ĄĮöĄŪ¦ā|├└į¬Ą─╩ął÷ęÄ─ŻĪŻ
ĪĪĪĪĪĪĪĪ
ĪĪĪĪ(3)═©▀^Ęų╬÷▒µūRšµŽÓ
ĪĪĪĪÕeš`ą┼Žó▓╗╚ńø]ėąą┼ŽóĪŻė╔ė┌ŠWĮjųąą┼ŽóĄ─é„▓źĖ³╝ė▒Ń└¹Ż¼╦∙ęįŠWĮj╠ō╝┘ą┼Žóįņ│╔Ą─╬Ż║”ę▓Ė³┤¾ĪŻ└²╚ńŻ¼2013─Ļ4į┬24╚šŻ¼├└┬ō╔ńTwitterÄż╠¢▒╗▒IŻ¼░l▓╝╠ō╝┘Ž¹ŽóĘQ┐éĮyŖW░═±RįŌ╩▄┐ų▓└ęuō¶╩▄é¹ĪŻļm╚╗╠ō╝┘Ž¹Žóį┌ÄūĘųńŖā╚▒╗Į¹ų╣Ż¼Ą½╩Ū╚į╚╗ę²░l┴╦├└ć°╣╔╩ąČ╠Ģ║╠°╦«ĪŻė╔ė┌┤¾öĄō■üĒį┤ÅVĘ║╝░ŲõČÓśėąįŻ¼į┌ę╗Č©│╠Č╚╔Ž╦³┐╔ęįÄ═ų·īŹ¼Fą┼ŽóĄ─╚źé╬┤µšµĪŻ─┐Ū░╚╦éāķ_╩╝ćLįć└¹ė├┤¾öĄō■▀Mąą╠ō╝┘ą┼ŽóūRäeĪŻ└²╚ńŻ¼╔ńĮ╗³cįuŅÉŠWšŠYelp└¹ė├┤¾öĄō■ī”╠ō╝┘įušō▀Mąą▀^×VŻ¼×ķė├æ¶╠ß╣®Ė³×ķšµīŹĄ─įušōą┼ŽóŻ╗Yahoo║═ThinkmailĄ╚└¹ė├┤¾öĄō■Ęų╬÷╝╝ągüĒ▀^×V└¼╗°Ó]╝■ĪŻ
2.3 ┤¾öĄō■╝╝ąg┐“╝▄
┤¾öĄō■╠Ä└Ē╔µ╝░öĄō■Ą─▓╔╝»Īó╣▄└ĒĪóĘų╬÷┼cš╣╩ŠĄ╚ĪŻłD1╩ŪŽÓĻP╝╝ąg╩ŠęŌłDĪŻ
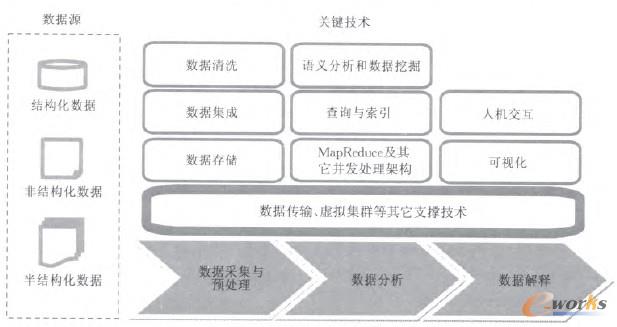
łD1 ┤¾öĄō■╝╝ąg╝▄śŗ
ĪĪĪĪ(1)öĄō■▓╔╝»┼cŅA╠Ä└Ē(Data Acquisition & Preparation)
ĪĪĪĪ┤¾öĄō■Ą─öĄō■į┤ČÓśė╗»Ż¼░³└©öĄō■ÄņĪó╬─▒ŠĪółDŲ¼ĪóęĢŅlĪóŠWĒōĄ╚Ė„ŅÉĮYśŗ╗»ĪóĘŪĮYśŗ╗»╝░░ļĮYśŗ╗»öĄō■ĪŻę“┤╦Ż¼┤¾öĄō■╠Ä└ĒĄ─Ą┌ę╗▓Į╩ŪÅ─öĄō■į┤▓╔╝»öĄō■▓ó▀MąąŅA╠Ä└Ē▓┘ū„Ż¼×ķ║¾└^┴„│╠╠ß╣®Įyę╗Ą─Ė▀┘|┴┐Ą─öĄō■╝»ĪŻ
ĪĪĪĪė╔ė┌┤¾öĄō■Ą─üĒį┤▓╗ę╗Ż¼┐╔─▄┤µį┌▓╗═¼─Ż╩ĮĄ─├Ķ╩÷Ż¼╔§ų┴┤µį┌├¼Č▄ĪŻę“┤╦Ż¼į┌öĄō■╝»│╔▀^│╠ųąī”öĄō■▀MąąŪÕŽ┤Ż¼ęįŽ¹│²ŽÓ╦ŲĪóųžÅ═╗“▓╗ę╗ų┬Ą─öĄō■╩ŪĘŪ│Ż▒žę¬Ą─ĪŻ╬─½IųąöĄō■ŪÕŽ┤║═╝»│╔╝╝ągßśī”┤¾öĄō■Ą─╠ž³cŻ¼╠ß│÷ĘŪĮYśŗ╗»╗“░ļĮYśŗ╗»öĄō■Ą─ŪÕŽ┤ęį╝░│¼┤¾ęÄ─ŻöĄō■Ą─╝»│╔ĪŻ
ĪĪĪĪöĄō■┤µā”┼c┤¾öĄō■æ¬ė├├▄ŪąŽÓĻPĪŻ─│ą®īŹĢrąįę¬Ū¾▌^Ė▀Ą─æ¬ė├Ż¼╚ńĀŅæB▒O┐žŻ¼Ė³▀m║Ž▓╔ė├┴„╠Ä└Ē─Ż╩ĮŻ¼ų▒Įėį┌ŪÕŽ┤║═╝»│╔║¾Ą─öĄō■į┤╔Ž▀MąąĘų╬÷ĪŻČ°┤¾ČÓöĄŲõ╦³æ¬ė├ätąĶę¬┤µā”Ż¼ęįų¦│ų║¾└^Ė³╔ŅČ╚Ą─öĄō■Ęų╬÷┴„│╠ĪŻ×ķ┴╦╠ßĖ▀öĄō■═╠═┬┴┐Ż¼ĮĄĄ═┤µā”│╔▒ŠŻ¼═©│Ż▓╔ė├Ęų▓╝╩Į╝▄śŗüĒ┤µā”┤¾öĄō■ĪŻ▀@ĘĮ├µėą┤·▒ĒąįĄ─蹊┐░³└©Ż║╬─╝■ŽĄĮyGFSEĪóHDFS║═HaystackĄ╚Ż╗NoSQLöĄō■ÄņMongodbĪóCouchDBĪóHBaseĪóRedisĪóNeo4jĄ╚ĪŻ
ĪĪĪĪ(2)öĄō■Ęų╬÷(Data Analysis)
ĪĪĪĪöĄō■Ęų╬÷╩Ū┤¾öĄō■æ¬ė├Ą─║╦ą─┴„│╠ĪŻĖ∙ō■▓╗═¼īė┤╬┤¾ų┬┐╔Ęų×ķ3ŅÉŻ║ėŗ╦Ń╝▄śŗĪó▓ķįā┼c╦„ę²ęį╝░öĄō■Ęų╬÷║═╠Ä└ĒĪŻ
ĪĪĪĪį┌ėŗ╦Ń╝▄śŗĘĮ├µŻ¼MapReduce╩Ū«öŪ░ÅVĘ║▓╔ė├Ą─┤¾öĄō■╝»ėŗ╦Ń─Żą═║═┐“╝▄ĪŻ×ķ┴╦▀mæ¬ę╗ą®ī”╚╬äš═Ļ│╔Ģrķgę¬Ū¾▌^Ė▀Ą─Ęų╬÷ąĶŪ¾Ż¼╬─½Iī”Ųõąį─▄▀Mąą┴╦ā×╗»Ż╗╬─½I╠ß│÷┴╦ę╗ĘN╗∙ė┌MapReduce╝▄śŗĄ─öĄō■┴„Ęų╬÷ĮŌøQĘĮ░ĖMARISSAŻ¼╩╣Ųõ─▄ē“ų¦│ųīŹĢrĘų╬÷╚╬䚯╗╬─½Iät╠ß│÷┴╦╗∙ė┌ĢrķgĄ─┤¾öĄō■Ęų╬÷ĘĮ░ĖMastiffŻ╗╬─½Ię▓ßśī”ÅVĖµ═Ų╦═Ą╚īŹĢrąįę¬Ū¾▌^Ė▀Ą─æ¬ė├Ż¼╠ß│÷┴╦╗∙ė┌MapReduceĄ─TiMR┐“╝▄üĒ▀MąąīŹĢr┴„╠Ä└ĒĪŻ
ĪĪĪĪį┌▓ķįā┼c╦„ę²ĘĮ├µŻ¼ė╔ė┌┤¾öĄō■ųą░³║¼┴╦┤¾┴┐Ą─ĘŪĮYśŗ╗»╗“░ļĮYśŗ╗»öĄō■Ż¼é„ĮyĻPŽĄą═öĄō■ÄņĄ─▓ķįā║═╦„ę²╝╝ąg╩▄ĄĮŽ▐ųŲŻ¼Č°NoSQLŅÉöĄō■Äņ╝╝ągĄ├ĄĮĖ³ČÓĻPūóĪŻ└²╚ńŻ¼╬─½I╠ß│÷┴╦ę╗éĆ╗ņ║ŽĄ─öĄō■įLå¢╝▄śŗHyDBęį╝░ę╗ĘN▓ó░löĄō■▓ķįā╝░ā×╗»ĘĮĘ©ĪŻ╬─½Iī”key-valueŅÉą═öĄō■ÄņĄ─▓ķįā▀Mąą┴╦ąį─▄ā×╗»ĪŻ
ĪĪĪĪį┌öĄō■Ęų╬÷┼c╠Ä└ĒĘĮ├µŻ¼ų„ę¬╔µ╝░Ą─╝╝ąg░³└©šZ┴xĘų╬÷┼cöĄō■═┌Š“Ą╚ĪŻė╔ė┌┤¾öĄō■ŁhŠ│Ž┬öĄō■│╩¼FČÓśė╗»╠ž³cŻ¼╦∙ęįī”öĄō■▀MąąšZ┴xĘų╬÷ĢrŻ¼Š═▌^ļyĮyę╗ągšZ▀MČ°═┌Š“ą┼ŽóĪŻ╬─½Ißśī”┤¾öĄō■ŁhŠ│Ż¼╠ß│÷┴╦ę╗ĘNĮŌøQągšZūā«Éå¢Ņ}Ą─Ė▀ą¦ągšZś╦£╩╗»ĘĮĘ©ĪŻ╬─½Iī”šZ┴xĘų╬÷ųąšZ┴x▒Š¾wĄ─«É┘|ąįš╣ķ_┴╦蹊┐ĪŻé„ĮyöĄō■═┌Š“╝╝ągų„ę¬ßśī”ĮYśŗ╗»öĄō■Ż¼ę“┤╦Ų╚ŪąąĶę¬ī”ĘŪĮYśŗ╗»╗“░ļĮYśŗ╗»Ą─öĄō■═┌Š“╝╝ągš╣ķ_蹊┐ĪŻ╬─½I╠ß│÷┴╦ę╗ĘNßśī”łDŲ¼╬─╝■Ą─═┌Š“╝╝ągŻ¼╬─½I╠ß│÷┴╦ę╗ĘN┤¾ęÄ─ŻTEXT╬─╝■Ą─Öz╦„║══┌Š“╝╝ągĪŻ
ĪĪĪĪ(3)öĄō■ĮŌßī(Data IntERPretation)
ĪĪĪĪöĄō■ĮŌßīų╝į┌Ė³║├Ąžų¦│ųė├æ¶ī”öĄō■Ęų╬÷ĮY╣¹Ą─╩╣ė├Ż¼╔µ╝░Ą─ų„ę¬╝╝ąg×ķ┐╔ęĢ╗»║═╚╦ÖCĮ╗╗źĪŻ─┐Ū░ęčĮøėą┴╦ę╗ą®ßśī”┤¾ęÄ─ŻöĄō■Ą─┐╔ęĢ╗»čąŠ┐Ż¼═©▀^öĄō■═Čė░ĪóŠSČ╚ĮĄĮŌ╗“’@╩Šē”Ą╚ĘĮĘ©üĒĮŌøQ┤¾ęÄ─ŻöĄō■Ą─’@╩Šå¢Ņ}ĪŻė╔ė┌╚╦ŅÉĄ─ęĢėX├¶ĖąČ╚Ž▐ųŲ┴╦Ė³┤¾Ų┴─╗’@╩ŠĄ─ėąą¦ąįŻ¼ęį╚╦×ķųąą─Ą─╚╦ÖCĮ╗╗źįOėŗę▓īó╩ŪĮŌøQ┤¾öĄō■Ęų╬÷ĮY╣¹š╣╩ŠĄ─ę╗ĘNųžę¬╝╝ągĪŻ
ĪĪĪĪ(4)Ųõ╦³ų¦ō╬╝╝ąg(Data Transmission & Virtual Cluster)
ĪĪĪĪļm╚╗┤¾öĄō■æ¬ė├ÅŖš{ęįöĄō■×ķųąą─Ż¼īóėŗ╦Ń═Ų╦═ĄĮöĄō■╔Žł╠ąąŻ¼Ą½╩Ūį┌š¹éĆ╠Ä└Ē▀^│╠ųąŻ¼öĄō■Ą─é„▌ö╚į╚╗╩Ū▒ž▓╗┐╔╔┘Ą─Ż¼└²╚ńę╗ą®┐ŲīWė^£yöĄō■Å─ė^£y³cŽ“öĄō■ųąą─Ą─é„▌öĄ╚ĪŻ╬─½Ißśī”┤¾öĄō■╠žš„蹊┐Ė▀ą¦é„▌ö╝▄śŗ║═ģfūhĪŻ
ĪĪĪĪ┤╦═ŌŻ¼ė╔ė┌╠ōöM╝»╚║Š▀ėą│╔▒ŠĄ═Īó┤ŅĮ©ņ`╗ŅĪó▒Ńė┌╣▄└ĒĄ╚ā׳cŻ¼╚╦éāį┌┤¾öĄō■Ęų╬÷Ģr┐╔ęį▀xō±Ė³╝ėĘĮ▒ŃĄ─╠ōöM╝»╚║üĒ═Ļ│╔Ė„ĒŚ╠Ä└Ē╚╬äšĪŻę“┤╦ąĶę¬ßśī”┤¾öĄō■æ¬ė├š╣ķ_Ą─╠ōöMÖC╝»╚║ā×╗»čąŠ┐ĪŻ
ĪĪĪĪ3.┤¾öĄō■ĦüĒĄ─░▓╚½╠¶æ
ĪĪĪĪ┐ŲīW╝╝ąg╩Ūę╗░čļp╚ąä”ĪŻ┤¾öĄō■╦∙ę²░lĄ─░▓╚½å¢Ņ}┼cŲõĦüĒĄ─ārųĄ═¼śėę²╚╦ūó─┐ĪŻČ°ūŅĮ³▒¼░lĄ─“└ŌńRķT”╩┬╝■Ė³╝ėäĪ┴╦╚╦éāī”┤¾öĄō■░▓╚½Ą─ō·ænĪŻ┼cé„ĮyĄ─ą┼Žó░▓╚½å¢Ņ}ŽÓ▒╚Ż¼┤¾öĄō■░▓╚½├µ┼RĄ─╠¶æąįå¢Ņ}ų„ę¬¾w¼Fį┌ęįŽ┬ÄūéĆĘĮ├µĪŻ
ĪĪĪĪ3.1 ┤¾öĄō■ųąĄ─ė├æ¶ļ[╦Į▒Żūo
ĪĪĪĪ┤¾┴┐╩┬īŹ▒Ē├„Ż¼┤¾öĄō■╬┤▒╗═ū╔Ų╠Ä└ĒĢ■ī”ė├æ¶Ą─ļ[╦Įįņ│╔śO┤¾Ą─Ūų║”ĪŻĖ∙ō■ąĶę¬▒ŻūoĄ─ā╚╚▌▓╗═¼Ż¼ļ[╦Į▒Żūoėų┐╔ęį▀Mę╗▓Į╝ÜĘų×ķ╬╗ų├ļ[╦Į▒ŻūoĪóś╦ūRĘ¹─õ├¹▒ŻūoĪó▀BĮėĻPŽĄ─õ├¹▒ŻūoĄ╚ĪŻ
ĪĪĪĪ╚╦éā├µ┼RĄ─═■├{▓ó▓╗āHŽ▐ė┌éĆ╚╦ļ[╦Įą╣┬®Ż¼▀Ćį┌ė┌╗∙ė┌┤¾öĄō■ī”╚╦éāĀŅæB║═ąą×ķĄ─ŅA£yĪŻę╗éĆĄõą═Ą─└²ūė╩Ū─│┴Ń╩█╔╠═©▀^Üv╩ĘėøõøĘų╬÷Ż¼▒╚╝ęķLĖ³įńų¬Ą└Ųõ┼«ā║ęčĮøæčįąĄ─╩┬īŹŻ¼▓óŽ“ŲõÓ]╝─ŽÓĻPÅVĖµą┼ŽóĪŻČ°╔ńĮ╗ŠWĮjĘų╬÷蹊┐ę▓▒Ē├„Ż¼┐╔ęį═©▀^ŲõųąĄ─╚║ĮM╠žąį░l¼Fė├æ¶Ą─ī┘ąįĪŻ└²╚ń═©▀^Ęų╬÷ė├æ¶Ą─Twitterą┼ŽóŻ¼┐╔ęį░l¼Fė├æ¶Ą─š■ų╬āAŽ“ĪóŽ¹┘M┴ĢæTęį╝░Ž▓║├Ą─Ū“ĻĀĄ╚ĪŻ
ĪĪĪĪ«öŪ░Ų¾śI│Ż│ŻšJ×ķĮø▀^─õ├¹╠Ä└Ē║¾Ż¼ą┼Žó▓╗░³║¼ė├æ¶Ą─ś╦ūRĘ¹Ż¼Š═┐╔ęį╣½ķ_░l▓╝┴╦ĪŻĄ½╩┬īŹ╔ŽŻ¼āH═©▀^─õ├¹▒Żūo▓ó▓╗─▄║▄║├Ąž▀_ĄĮļ[╦Į▒Żūo─┐ś╦ĪŻ└²╚ńŻ¼AOL╣½╦Šį°╣½▓╝┴╦─õ├¹╠Ä└Ē║¾Ą─3éĆį┬ā╚▓┐Ęų╦č╦„Üv╩ĘŻ¼╣®╚╦éāĘų╬÷╩╣ė├ĪŻļm╚╗éĆ╚╦ŽÓĻPĄ─ś╦ūRą┼Žó▒╗Š½ą─╠Ä└Ē▀^Ż¼Ą½ŲõųąĄ──│ą®ėøõøĒŚ▀Ć╩Ū┐╔ęį▒╗£╩┤_ĄžČ©╬╗ĄĮŠ▀¾wĄ─éĆ╚╦ĪŻ╝~╝sĢrł¾ļS╝┤╣½▓╝┴╦ŲõūRäe│÷Ą─1╬╗ė├æ¶ĪŻŠÄ╠¢×ķ4417 749Ą─ė├æ¶╩Ū1╬╗62ÜqĄ─╣čŠėŗD╚╦Ż¼╝ę└’B┴╦3Śl╣ĘŻ¼╗╝ėą─│ĘN╝▓▓ĪŻ¼Ą╚Ą╚ĪŻ┴Ēę╗éĆŽÓ╦ŲĄ─└²ūė╩ŪŻ¼ų°├¹Ą─DVDūŌ┘U╔╠Netflixį°╣½▓╝┴╦╝s50╚fė├æ¶Ą─ūŌ┘Uą┼ŽóŻ¼æę┘p100╚f├└į¬š„╝»╦ŃĘ©Ż¼ęįŲ┌╠ßĖ▀ļŖė░═Ų╦]ŽĄĮyĄ─£╩┤_Č╚ĪŻĄ½╩Ū«ö╔Ž╩÷ą┼Žó┼cŲõ╦³öĄō■į┤ĮY║ŽĢrŻ¼▓┐Ęųė├æ¶▀Ć╩Ū▒╗ūRäe│÷üĒ┴╦ĪŻčąŠ┐š▀░l¼FŻ¼NetflixųąĄ─ė├æ¶ėą║▄┤¾Ė┼┬╩ī”ĘŪtopl00Īótop500Īótopl000Ą─ė░Ų¼▀Mąą▀^įuĘųŻ¼Č°Ė∙ō■ī”ĘŪtopė░Ų¼Ą─įuĘųĮY╣¹▀Mąą╚ź─õ├¹╗»(de-anonymizing)╣źō¶Ą─ą¦╣¹Ė³║├ĪŻ
ĪĪĪĪ─┐Ū░ė├æ¶öĄō■Ą─╩š╝»Īó┤µā”Īó╣▄└Ē┼c╩╣ė├Ą╚Š∙╚▒Ę”ęÄĘČŻ¼Ė³╚▒Ę”▒O╣▄Ż¼ų„ę¬ę└┐┐Ų¾śIĄ─ūį┬╔ĪŻė├涤oĘ©┤_Č©ūį╝║ļ[╦Įą┼ŽóĄ─ė├═ŠĪŻČ°į┌╔╠śI╗»ł÷Š░ųąŻ¼ė├æ¶æ¬ėąÖÓøQČ©ūį╝║Ą─ą┼Žó╚ń║╬▒╗└¹ė├Ż¼īŹ¼Fė├æ¶┐╔┐žĄ─ļ[╦Į▒ŻūoĪŻ└²╚ńė├æ¶┐╔ęįøQČ©ūį╝║Ą─ą┼Žó║╬Ģręį║╬ĘNą╬╩Į┼¹┬ČŻ¼║╬Ģr▒╗õNܦĪŻ░³└©Ż║(1)öĄō■▓╔╝»ĢrĄ─ļ[╦Į▒ŻūoŻ¼╚ńöĄō■Š½Č╚╠Ä└ĒŻ╗(2)öĄō■╣▓ŽĒĪó░l▓╝ĢrĄ─ļ[╦Į▒ŻūoŻ¼╚ńöĄō■Ą──õ├¹╠Ä└ĒĪó╚╦╣ż╝ėö_Ą╚Ż╗(3)öĄō■Ęų╬÷ĢrĄ─ļ[╦Į▒ŻūoŻ╗(4)öĄō■╔·├³ų▄Ų┌Ą─ļ[╦Į▒ŻūoŻ╗(5)ļ[╦ĮöĄō■┐╔ą┼õNܦĄ╚ĪŻ
ĪĪĪĪ3.2 ┤¾öĄō■Ą─┐╔ą┼ąį
ĪĪĪĪĻPė┌┤¾öĄō■Ą─ę╗éĆŲš▒ķĄ─ė^³c╩ŪŻ¼öĄō■ūį╝║┐╔ęįšf├„ę╗ŪąŻ¼öĄō■ūį╔ĒŠ═╩Ū╩┬īŹĪŻĄ½īŹļHŪķør╩ŪŻ¼╚ń╣¹▓╗ūą╝ÜšńäeŻ¼öĄō■ę▓Ģ■Ų█“_Ż¼Š═Ž±╚╦éāėąĢrĢ■▒╗ūį╝║Ą─ļpč█Ų█“_ę╗śėĪŻ
ĪĪĪĪ┤¾öĄō■┐╔ą┼ąįĄ─═■├{ų«ę╗╩Ūé╬įņ╗“┐╠ęŌųŲįņĄ─öĄō■Ż¼Č°Õeš`Ą─öĄō■═∙═∙Ģ■ī¦ų┬Õeš`Ą─ĮYšōĪŻ╚¶öĄō■æ¬ė├ł÷Š░├„┤_Ż¼Š═┐╔─▄ėą╚╦┐╠ęŌųŲįņöĄō■ĪóĀIįņ─│ĘN“╝┘Ž¾”Ż¼šTī¦Ęų╬÷š▀Ą├│÷ī”Ųõėą└¹Ą─ĮYšōĪŻė╔ė┌╠ō╝┘ą┼Žó═∙═∙ļ[▓žė┌┤¾┴┐ą┼ŽóųąŻ¼╩╣Ą├╚╦éā¤oĘ©Ķbäešµé╬Ż¼Å─Č°ū÷│÷Õeš`┼ąöÓĪŻ└²╚ńŻ¼ę╗ą®³cįuŠWšŠ╔ŽĄ─╠ō╝┘įušōŻ¼╗ņļsį┌šµīŹįušōųą╩╣Ą├ė├涤oĘ©Ęų▒µŻ¼┐╔─▄š`ī¦ė├æ¶╚ź▀xō±─│ą®┴ė┘|╔╠ŲĘ╗“Ę■äšĪŻė╔ė┌«öŪ░ŠWĮj╔ńģ^ųą╠ō╝┘ą┼ŽóĄ─«a╔·║═é„▓źūāĄ├įĮüĒįĮ╚▌ęūŻ¼Ųõ╦∙«a╔·Ą─ė░Ēæ▓╗┐╔Ą═╣└ĪŻė├ą┼Žó░▓╚½╝╝ąg╩ųČ╬Ķbäe╦∙ėąüĒį┤Ą─šµīŹąį╩Ū▓╗┐╔─▄Ą─ĪŻ
ĪĪĪĪ┤¾öĄō■┐╔ą┼ąįĄ─═■├{ų«Č■╩ŪöĄō■į┌é„▓źųąĄ─ų▓Į╩¦šµĪŻįŁę“ų«ę╗╩Ū╚╦╣żĖ╔ŅAĄ─öĄō■▓╔╝»▀^│╠┐╔─▄ę²╚ļš`▓ŅŻ¼ė╔ė┌╩¦š`ī¦ų┬öĄō■╩¦šµ┼cŲ½▓ŅŻ¼ūŅĮKė░ĒæöĄō■Ęų╬÷ĮY╣¹Ą─£╩┤_ąįĪŻ┤╦═ŌŻ¼öĄō■╩¦šµ▀ĆėąöĄō■Ą─░µ▒ŠūāĖ³Ą─ę“╦žĪŻį┌é„▓ź▀^│╠ųąŻ¼¼FīŹŪķør░l╔·┴╦ūā╗»Ż¼įńŲ┌▓╔╝»Ą─öĄō■ęčĮø▓╗─▄Ę┤ė│šµīŹŪķørĪŻ└²╚ńŻ¼▓═^ļŖįÆ╠¢┤aęčĮøūāĖ³Ż¼Ą½įńŲ┌Ą─ą┼ŽóęčĮø▒╗Ųõ╦³╦č╦„ę²Ūµ╗“æ¬ė├╩šõøŻ¼╦∙ęįė├æ¶┐╔─▄┐┤ĄĮ├¼Č▄Ą─ą┼ŽóČ°ė░ĒæŲõ┼ąöÓĪŻ
ĪĪĪĪę“┤╦Ż¼┤¾öĄō■Ą─╩╣ė├š▀æ¬įōėą─▄┴”╗∙ė┌öĄō■üĒį┤Ą─šµīŹąįĪóöĄō■é„▓ź═ŠÅĮĪóöĄō■╝ė╣ż╠Ä└Ē▀^│╠Ą╚Ż¼┴╦ĮŌĖ„ĒŚöĄō■┐╔ą┼Č╚Ż¼Ę└ų╣Ęų╬÷Ą├│÷¤oęŌ┴x╗“š▀Õeš`Ą─ĮY╣¹ĪŻ
ĪĪĪĪ├▄┤aīWųąĄ─öĄūų║×├¹Ī󎹎óĶbäe┤aĄ╚╝╝ąg┐╔ęįė├ė┌“×ūCöĄō■Ą─═Ļš¹ąįŻ¼Ą½æ¬ė├ė┌┤¾öĄō■Ą─šµīŹąįĢr├µ┼R║▄┤¾└¦ļyŻ¼ų„ę¬Ė∙į┤į┌ė┌öĄō■┴ŻČ╚Ą─▓Ņ«ÉĪŻ└²╚ńŻ¼öĄō■Ą─░lį┤ĘĮ┐╔ęįī”š¹éĆą┼Žó║×├¹Ż¼Ą½╩Ū«öą┼ŽóĘųĮŌ│╔╚¶Ė╔ĮM│╔▓┐ĘųĢrŻ¼įō║×├¹¤oĘ©“×ūC├┐éĆ▓┐ĘųĄ─═Ļš¹ąįĪŻČ°öĄō■Ą─░lį┤ĘĮ¤oĘ©╩┬Ž╚ŅAų¬──ą®▓┐Ęų▒╗└¹ė├Īó╚ń║╬▒╗└¹ė├Ż¼ļyęį╩┬Ž╚×ķŲõ╔·│╔“×ūCī”Ž¾ĪŻ
ĪĪĪĪ3.3 ╚ń║╬īŹ¼F┤¾öĄō■įLå¢┐žųŲ
ĪĪĪĪįLå¢┐žųŲ╩ŪīŹ¼FöĄō■╩▄┐ž╣▓ŽĒĄ─ėąą¦╩ųČ╬ĪŻė╔ė┌┤¾öĄō■┐╔─▄▒╗ė├ė┌ČÓĘN▓╗═¼ł÷Š░Ż¼ŲõįLå¢┐žųŲąĶŪ¾╩«Ęų═╗│÷ĪŻ
ĪĪĪĪ┤¾öĄō■įLå¢┐žųŲĄ─╠ž³c┼cļy³cį┌ė┌Ż║
ĪĪĪĪ(1)ļyęįŅAįOĮŪ╔½Ż¼īŹ¼FĮŪ╔½äØĘųĪŻė╔ė┌┤¾öĄō■æ¬ė├ĘČć·ÅVĘ║Ż¼╦³═©│Żę¬×ķüĒūį▓╗═¼ĮM┐Ś╗“▓┐ķTĪó▓╗═¼╔ĒĘ▌┼c─┐Ą─Ą─ė├æ¶╦∙įLå¢Ż¼īŹ╩®įLå¢┐žųŲ╩Ū╗∙▒ŠąĶŪ¾ĪŻ╚╗Č°Ż¼į┌┤¾öĄō■Ą─ł÷Š░Ž┬Ż¼ėą┤¾┴┐Ą─ė├æ¶ąĶę¬īŹ╩®ÖÓŽ▐╣▄└ĒŻ¼Ūęė├涊▀¾wĄ─ÖÓŽ▐ę¬Ū¾╬┤ų¬ĪŻ├µī”╬┤ų¬Ą─┤¾┴┐öĄō■║═ė├æ¶Ż¼ŅAŽ╚įOų├ĮŪ╔½╩«Ęų└¦ļyĪŻ
ĪĪĪĪ(2)ļyęįŅAų¬├┐éĆĮŪ╔½Ą─īŹļHÖÓŽ▐ĪŻė╔ė┌┤¾öĄō■ł÷Š░ųą░³║¼║Ż┴┐öĄō■Ż¼░▓╚½╣▄└ĒåT┐╔─▄╚▒Ę”ūŃē“Ą─īŻśIų¬ūRŻ¼¤oĘ©£╩┤_Ąž×ķė├æ¶ųĖČ©Ųõ╦∙┐╔ęįįLå¢Ą─öĄō■ĘČć·ĪŻČ°ŪęÅ─ą¦┬╩ĮŪČ╚ųvŻ¼Č©┴xė├æ¶╦∙ėą╩┌ÖÓęÄätę▓▓╗╩Ū└ĒŽļĄ─ĘĮ╩ĮĪŻęįßt»¤ŅIė“æ¬ė├×ķ└²Ż¼ßt╔·×ķ┴╦═Ļ│╔Ųõ╣żū„┐╔─▄ąĶę¬įLå¢┤¾┴┐ą┼ŽóŻ¼Ą½ī”ė┌öĄō■─▄ʱįLå¢æ¬įōė╔ßt╔·üĒøQČ©Ż¼▓╗æ¬įōąĶę¬╣▄└ĒåTī”├┐éĆßt╔·ū÷╠žäeĄ─┼õų├ĪŻĄ½═¼Ģrėųæ¬įō─▄ē“╠ß╣®ī”ßt╔·įLå¢ąą×ķĄ─Öz£y┼c┐žųŲŻ¼Ž▐ųŲßt╔·ī”▓Ī╗╝öĄō■Ą─▀^Č╚įLå¢ĪŻ
ĪĪĪĪ┤╦═ŌŻ¼▓╗═¼ŅÉą═Ą─┤¾öĄō■ųą┐╔─▄┤µį┌ČÓśė╗»Ą─įLå¢┐žųŲąĶŪ¾ĪŻ└²╚ńŻ¼į┌Web2.0éĆ╚╦ė├æ¶öĄō■ųąŻ¼┤µį┌╗∙ė┌Üv╩ĘėøõøĄ─įLå¢┐žųŲŻ╗į┌Ąž└ĒĄžłDöĄō■ųąŻ¼┤µį┌╗∙ė┌│▀Č╚ęį╝░öĄō■Š½Č╚Ą─įLå¢┐žųŲąĶŪ¾Ż╗į┌┴„öĄō■╠Ä└ĒųąŻ¼┤µį┌öĄō■Ģrķgģ^ķgĄ─įLå¢┐žųŲąĶŪ¾Ż¼Ą╚Ą╚ĪŻ╚ń║╬Įyę╗Ąž├Ķ╩÷┼c▒Ē▀_įLå¢┐žųŲąĶŪ¾ę▓╩Ūę╗éĆ╠¶æąįå¢Ņ}ĪŻ
ĪĪĪĪ4.┤¾öĄō■░▓╚½┼cļ[╦Į▒ŻūoĻPµI╝╝ąg
ĪĪĪĪ«öŪ░žĮąĶßśī”Ū░╩÷┤¾öĄō■├µl┼RĄ─ė├æ¶ļ[╦Į▒ŻūoĪóöĄō■ā╚╚▌┐╔ą┼“×ūCĪóįLå¢┐žųŲĄ╚░▓╚½╠¶æŻ¼š╣ķ_┤¾öĄō■░▓╚½ĻPµI╝╝ąg蹊┐ĪŻ▒Š╣Ø▀x╚Ī▓┐Ęųųž³cŽÓĻP蹊┐ŅIė“ėĶęįĮķĮBĪŻ
ĪĪĪĪ4.1 öĄō■░l▓╝─õ├¹▒Żūo╝╝ąg
ĪĪĪĪī”ė┌┤¾öĄō■ųąĄ─ĮYśŗ╗»öĄō■(╗“ĘQĻPŽĄöĄō■)Č°čįŻ¼öĄō■░l▓╝─õ├¹▒Żūo╩ŪīŹ¼FŲõļ[╦Į▒ŻūoĄ─║╦ą─ĻPµI╝╝ąg┼c╗∙▒Š╩ųČ╬Ż¼─┐Ū░╚į╠Äė┌▓╗öÓ░lš╣┼c═Ļ╔ŲļAČ╬ĪŻęįĄõą═Ą─k─õ├¹ĘĮ░Ė×ķ└²ĪŻįńŲ┌Ą─ĘĮ░Ė╝░Ųõā×╗»ĘĮ░Ė═©▀^į¬ĮMĘ║╗»ĪóęųųŲĄ╚öĄō■╠Ä└ĒŻ¼īó£╩ś╦ūRĘ¹ĘųĮMĪŻ├┐éĆĘųĮMųąĄ─£╩ś╦ūRĘ¹ŽÓ═¼Ūęų┴╔┘░³║¼kéĆį¬ĮMŻ¼ę“Č°├┐éĆį¬ĮMų┴╔┘┼ck-1éĆŲõ╦³į¬ĮM▓╗┐╔ģ^ĘųĪŻė╔ė┌╩Ū─õ├¹─Żą═╩Ūßśī”╦∙ėąī┘ąį╝»║ŽČ°čįŻ¼ī”ė┌Š▀¾wĄ──│éĆī┘ąįät╬┤╝ėČ©┴xŻ¼╚▌ęū│÷¼F─│éĆī┘ąį─õ├¹╠Ä└Ē▓╗ūŃĄ─ŪķørĪŻ╚¶─│Ą╚ārŅÉųą─│éĆ├¶Ėąī┘ąį╔Ž╚ĪųĄę╗ų┬Ż¼ät╣źō¶š▀┐╔ęįėąą¦Ąž┤_Č©įōī┘ąįųĄĪŻßśī”įōå¢Ņ}蹊┐š▀╠ß│÷lČÓśė╗»(l-diversity)─õ├¹ĪŻŲõ╠ž³c╩Ūį┌├┐ę╗éĆ─õ├¹ī┘ąįĮM└’├¶ĖąöĄō■Ą─ČÓśėąįØMūŃę¬┤¾ė┌╗“Ą╚ė┌lĪŻīŹ¼FĘĮĘ©░³└©╗∙ė┌▓├╝¶╦ŃĘ©Ą─ĘĮ░Ėęį╝░╗∙ė┌öĄō■ų├ōQĄ─ĘĮ░ĖĄ╚ĪŻ┤╦═ŌŻ¼▀Ćėąę╗ą®Įķė┌ųŠ─õ├¹┼clČÓśė╗»ų«ķgĄ─ĘĮ░ĖĪŻ▀Mę╗▓ĮĄ─Ż¼ė╔ė┌l-diversityų╗╩Ū─▄ē“▒M┴┐╩╣├¶ĖąöĄō■│÷¼FĄ─Ņl┬╩ŲĮŠ∙╗»ĪŻ«ö═¼ę╗Ą╚ārŅÉųąöĄō■ĘČć·║▄ąĪĢrŻ¼╣źō¶š▀┐╔▓┬£yŲõųĄĪŻt┘NĮ³ąį(t-closeness)ĘĮ░Ėę¬Ū¾Ą╚ārŅÉųą├¶ĖąöĄō■Ą─Ęų▓╝┼cš¹éĆöĄō■▒ĒųąöĄō■Ą─Ęų▓╝▒Ż│ųę╗ų┬ĪŻŲõ╦³╣żū„░³└©(kŻ¼e)─õ├¹─Żą═(XŻ¼Y)─õ├¹─Żą═Ą╚ĪŻ╔Ž╩÷蹊┐╩Ūßśī”ņoæBĪóę╗┤╬ąį░l▓╝ŪķørĪŻČ°¼FīŹųąŻ¼öĄō■░l▓╝│Ż├µ┼RöĄō■▀B└mĪóČÓ┤╬░l▓╝Ą─ł÷Š░ĪŻąĶę¬Ę└ų╣╣źō¶š▀ī”ČÓ┤╬░l▓╝Ą─öĄō■┬ō║Ž▀MąąĘų╬÷Ż¼ŲŲē─öĄō■įŁėąĄ──õ├¹╠žąįĪŻ
ĪĪĪĪį┌┤¾öĄō■ł÷Š░ųąŻ¼öĄō■░l▓╝─õ├¹▒Żūoå¢Ņ}▌^ų«Ė³×ķÅ═ļsŻ║╣źō¶š▀┐╔ęįÅ─ČÓĘNŪ■Ą└½@Ą├öĄō■Ż¼Č°▓╗āHāH╩Ū═¼ę╗░l▓╝į┤ĪŻ└²╚ńŻ¼į┌Ū░╦∙╠ß╝░Ą─Netflixæ¬ė├ųąŻ¼╚╦éā░l¼F╣źō¶š▀┐╔═©▀^īóöĄō■┼c╣½ķ_┐╔½@Ą├Ą─imdbŽÓī”▒╚Ż¼Å─Č°ūRäe│÷─┐ś╦į┌NetflixĄ─┘~╠¢ĪŻ▓óō■┤╦½@╚Īė├æ¶Ą─š■ų╬āAŽ“┼cū┌Į╠ą┼č÷Ą╚(═©▀^ė├æ¶Ą─ė^┐┤Üv╩Ę║═ī”─│ą®ļŖė░Ą─įušō║═┤“ĘųĘų╬÷½@Ą├)ĪŻ┤╦ŅÉå¢Ņ}ėą┤²Ė³╔Ņ╚ļĄ─蹊┐ĪŻ
ĪĪĪĪ4.2 ╔ńĮ╗ŠWĮj─õ├¹▒Żūo╝╝ąg
ĪĪĪĪ╔ńĮ╗ŠWĮj«a╔·Ą─öĄō■╩Ū┤¾öĄō■Ą─ųžę¬üĒį┤ų«ę╗Ż¼═¼Ģr▀@ą®öĄō■ųą░³║¼┤¾┴┐ė├æ¶ļ[╦ĮöĄō■ĪŻĮžų┴2012─Ļ10į┬FacebookĄ─ė├æ¶│╔åTŠ═ęč▀_10ā|ĪŻė╔ė┌╔ńĮ╗ŠWĮjŠ▀ėąłDĮYśŗ╠žš„Ż¼Ųõ─õ├¹▒Żūo╝╝ąg┼cĮYśŗ╗»öĄō■ėą║▄┤¾▓╗═¼ĪŻ
ĪĪĪĪ╔ńĮ╗ŠWĮjųąĄ─Ąõą═─õ├¹▒ŻūoąĶŪ¾×ķė├æ¶ś╦ūR─õ├¹┼cī┘ąį─õ├¹(ėųĘQ³c─õ├¹)Ż¼į┌öĄō■░l▓╝Ģrļ[▓ž┴╦ė├æ¶Ą─ś╦ūR┼cī┘ąįą┼ŽóŻ╗ęį╝░ė├æ¶å¢ĻPŽĄ─õ├¹(ėųĘQ▀ģ─õ├¹)Ż¼į┌öĄō■░l▓╝Ģrļ[▓žė├æ¶ķgĄ─ĻPŽĄĪŻČ°╣źō¶š▀įćłD└¹ė├╣سcĄ─Ė„ĘNī┘ąį(Č╚öĄĪóś╦║×Īó─│ą®Š▀¾w▀BĮėą┼ŽóĄ╚)Ż¼ųžą┬ūRäe│÷łDųą╣سcĄ─╔ĒĘ▌ą┼ŽóĪŻ
ĪĪĪĪ─┐Ū░Ą─▀ģ─õ├¹ĘĮ░Ė┤¾ČÓ╩Ū╗∙ė┌▀ģĄ─į÷ähĪŻļSÖCį÷ähĮ╗ōQ▀ģĄ─ĘĮĘ©┐╔ęįėąą¦ĄžīŹ¼F▀ģ─õ├¹ĪŻŲõųą╬─½Iį┌─õ├¹▀^│╠ųą▒Ż│ųÓÅĮėŠžĻćĄ─╠žš„ųĄ║═ī”æ¬Ą─└ŁŲš└Ł╦╣ŠžĻćĄ┌Č■╠žš„ųĄ▓╗ūāŻ¼╬─½IĖ∙ō■╣سcĄ─Č╚öĄĘųĮMŻ¼Å─Č╚öĄŽÓ═¼Ą─╣سcųą▀xō±Ę¹║Žę¬Ū¾Ą─▀Mąą▀ģĄ─Į╗ōQŻ¼ŅÉ╦ŲĄ─▀Ćėą╬─½IĪŻ▀@ŅÉĘĮĘ©Ą─å¢Ņ}╩ŪļSÖCį÷╝ėĄ─įļę¶▀^ė┌Ęų╔óŽĪ╔┘Ż¼┤µį┌─õ├¹▀ģ▒Żūo▓╗ūŃå¢Ņ}ĪŻ
ĪĪĪĪ┴Ēę╗éĆųžę¬╦╝┬Ę╩Ū╗∙ė┌│¼╝ē╣سcī”łDĮYśŗ▀MąąĘųĖŅ║═╝»Š█▓┘ū„ĪŻ╚ń╗∙ė┌╣سcŠ█╝»Ą──õ├¹ĘĮ░ĖĪó╗∙ė┌╗∙ę“╦ŃĘ©Ą─īŹ¼FĘĮ░ĖĪó╗∙ė┌─ŻöM═╦╗╦ŃĘ©Ą─īŹ¼FĘĮ░Ė▓Ėéāęį╝░Ž╚╠Ņ│õį┘ĘųĖŅ│¼╝ē╣سcĄ─ĘĮ░ĖĪŻ╬─½I╦∙╠ß│÷Ą─k-securityĖ┼─ŅŻ¼═©▀^kéĆ═¼śŗūėłDīŹ¼FłD─õ├¹▒ŻūoĪŻ╗∙ė┌│¼╝ē╣سcĄ──õ├¹ĘĮ░Ėļm╚╗─▄ē“īŹ¼F▀ģĄ──õ├¹Ż¼Ą½╩Ū┼cįŁ╩╝╔ńĮ╗ĮYśŗłD┤µį┌▌^┤¾ģ^äeŻ¼ęįĀ▐╔³öĄō■Ą─┐╔ė├ąį×ķ┤·ārĪŻ
ĪĪĪĪ╔ńĮ╗ŠWĮj─õ├¹ĘĮ░Ė├µ┼RĄ─ųžę¬å¢Ņ}╩ŪŻ¼╣źō¶š▀┐╔─▄═©▀^Ųõ╦³╣½ķ_Ą─ą┼Žó═Ų£y│÷─õ├¹ė├æ¶Ż¼ė╚Ųõ╩Ūė├æ¶ų«ķg╩Ūʱ┤µį┌▀BĮėĻPŽĄĪŻ└²╚ńŻ¼┐╔ęį╗∙ė┌╚§▀BĮėī”ė├æ¶┐╔─▄┤µį┌Ą─▀BĮė▀MąąŅA£yŻ¼▀mė├ė┌ė├æ¶ĻPŽĄ▌^×ķŽĪ╩ĶĄ─ŠWĮjŻ╗Ė∙ō■¼Fėą╔ńĮ╗ĮYśŗī”╚╦╚║ųąĄ─Ą╚╝ēĻPŽĄ▀Mąą╗ųÅ═║══Ų£yŻ╗ßśī”╬ó▓®ą═Ą─Å═║Ž╔ńĮ╗ŠWĮj▀MąąĘų╬÷┼cĻPŽĄŅA£yŻ╗╗∙ė┌Ž▐ųŲļSÖCė╬ū▀ĘĮĘ©Ż¼═Ų£y▓╗═¼▀BĮėĻPŽĄ┤µį┌Ą─Ė┼┬╩Ż¼Ą╚Ą╚ĪŻčąŠ┐▒Ē├„Ż¼╔ńĮ╗ŠWĮjĄ─╝»Š█╠žąįī”ė┌ĻPŽĄŅA£yĘĮĘ©Ą─£╩┤_ąįŠ▀ėąųžę¬ė░ĒæŻ¼╔ńĮ╗ŠWĮjŠų▓┐▀BĮė├▄Č╚į÷ķLŻ¼╝»Š█ŽĄöĄį÷┤¾Ż¼ät▀BĮėŅA£y╦ŃĘ©Ą─£╩┤_ąį▀Mę╗▓Įį÷ÅŖĪŻę“┤╦Ż¼╬┤üĒĄ──õ├¹▒Żūo╝╝ągæ¬┐╔ęįėąą¦Ąų┐╣┤╦ŅÉ═Ų£y╣źō¶ĪŻ
ĪĪĪĪ4.3 öĄō■╦«ėĪ╝╝ąg
ĪĪĪĪöĄūų╦«ėĪ╩ŪųĖīóś╦ūRą┼Žóęįļyęį▓ņėXĄ─ĘĮ╩ĮŪČ╚ļį┌öĄō■▌d¾wā╚▓┐Ūę▓╗ė░ĒæŲõ╩╣ė├Ą─ĘĮĘ©Ż¼ČÓęŖė┌ČÓ├Į¾wöĄō■░µÖÓ▒ŻūoĪŻę▓ėą▓┐Ęųßśī”öĄō■Äņ║═╬─▒Š╬─╝■Ą─╦«ėĪĘĮ░ĖĪŻ
ĪĪĪĪė╔öĄō■Ą─¤oą“ąįĪóäėæBąįĄ╚╠ž³c╦∙øQČ©Ż¼į┌öĄō■ÄņĪó╬─Önųą╠Ē╝ė╦«ėĪĄ─ĘĮĘ©┼cČÓ├Į¾w▌d¾w╔Žėą║▄┤¾▓╗═¼ĪŻŲõ╗∙▒ŠŪ░╠ß╩Ū╔Ž╩÷öĄō■ųą┤µį┌╚▀ėÓą┼Žó╗“┐╔╚▌╚╠ę╗Č©Š½Č╚š`▓ŅĪŻ└²╚ńŻ¼AgrawalĄ╚╚╦╗∙ė┌öĄō■ÄņųąöĄųĄą═öĄō■┤µį┌š`▓Ņ╚▌╚╠ĘČć·Ż¼īó╔┘┴┐╦«ėĪą┼ŽóŪČ╚ļĄĮ▀@ą®öĄō■ųąļSÖC▀x╚ĪĄ─ūŅ▓╗ųžę¬╬╗╔ŽĪŻČ°SionĄ╚╚╦╠ß│÷ę╗ĘN╗∙ė┌öĄō■╝»║ŽĮyėŗ╠žš„Ą─ĘĮ░ĖŻ¼īóę╗▒╚╠ž╦«ėĪą┼ŽóŪČ╚ļį┌ę╗ĮMī┘ąįöĄō■ųąŻ¼Ę└ų╣╣źō¶š▀ŲŲē─╦«ėĪĪŻ┤╦═ŌŻ¼═©▀^īóöĄō■ÄņųĖ╝yą┼ŽóŪČ╚ļ╦«ėĪųąŻ¼┐╔ęįūRäe│÷ą┼ŽóĄ─╦∙ėąš▀ęį╝░▒╗Ęų░lĄ─ī”Ž¾Ż¼ėą└¹ė┌į┌Ęų▓╝╩ĮŁhŠ│Ž┬ūĘ█Öą╣├▄š▀Ż╗═©▀^▓╔ė├¬Ü┴óĘų┴┐Ęų╬÷╝╝ąg(║åĘQICA)Ż¼┐╔ęįīŹ¼F¤oąĶ├▄ĶĆĄ─╦«ėĪ╣½ķ_“×ūCĪŻ╚¶į┌öĄō■Äņ▒ĒųąŪČ╚╦┤Ó╚§ąį╦«ėĪŻ¼┐╔ęįÄ═ų·╝░Ģr░l¼FöĄō■ĒŚĄ─ūā╗»ĪŻ
ĪĪĪĪ╬─▒Š╦«ėĪĄ─╔·│╔ĘĮĘ©ĘNŅÉ║▄ČÓŻ¼┐╔┤¾ų┬Ęų×ķ╗∙ė┌╬─ÖnĮYśŗ╬óš{Ą─╦«ėĪŻ¼ę└┘ćūųĘ¹ķgŠÓ┼cąąķgŠÓĄ╚Ė±╩Į╔ŽĄ─╬óąĪ▓Ņ«ÉŻ╗╗∙ė┌╬─▒Šā╚╚▌Ą─╦«ėĪŻ¼ę└┘ćė┌ą▐Ė─╬─Önā╚╚▌Ż¼╚ńį÷╝ė┐šĖ±Īóą▐Ė─ś╦³cĄ╚Ż╗ęį╝░╗∙ė┌ūį╚╗šZčįĄ─╦«ėĪĪŻ═©▀^└ĒĮŌšZ┴xīŹ¼Fūā╗»Ż¼╚ń═¼┴xį~╠µōQ╗“Šõ╩Įūā╗»Ą╚ĪŻ
ĪĪĪĪ╔Ž╩÷╦«ėĪĘĮ░Ėųąėąą®┐╔ė├ė┌▓┐ĘųöĄō■Ą─“×ūCĪŻ└²╚ńį┌╬─½IųąŻ¼ÜłėÓį¬ĮMöĄ┴┐▀_ĄĮķōųĄŠ═┐╔ęį│╔╣”“×ūC│÷╦«ėĪĪŻįō╠žąįį┌┤¾öĄō■æ¬ė├ł÷Š░Ž┬Š▀ėąÅVķ¤Ą─░lš╣Ū░Š░Ż¼└²╚ńŻ║ÅŖĮĪ╦«ėĪŅÉ(RobustWatermark)┐╔ė├ė┌┤¾öĄō■Ą─Ųį┤ūC├„Ż¼Č°┤Ó╚§╦«ėĪŅÉ(Fragile Watermark)┐╔ė├ė┌┤¾öĄō■Ą─šµīŹąįūC├„ĪŻ┤µį┌å¢Ņ}ų«ę╗╩Ū«öŪ░Ą─ĘĮ░ĖČÓ╗∙ė┌ņoæBöĄō■╝»Ż¼ßśī”┤¾öĄō■Ą─Ė▀╦┘«a╔·┼cĖ³ą┬Ą─╠žąį┐╝æ]▓╗ūŃŻ¼▀@╩Ū╬┤üĒžĮ┤²╠ßĖ▀Ą─ĘĮŽ“ĪŻ
ĪĪĪĪ4.4 öĄō■╦▌į┤╝╝ąg
ĪĪĪĪ╚ńŪ░╦∙╩÷Ż¼öĄō■╝»│╔╩Ū┤¾öĄō■Ū░Ų┌╠Ä└ĒĄ─▓Į¾Eų«ę╗ĪŻė╔ė┌öĄō■Ą─üĒį┤ČÓśė╗»Ż¼╦∙ęįėą▒žę¬ėøõøöĄō■Ą─üĒį┤╝░Ųõé„▓źĪóėŗ╦Ń▀^│╠Ż¼×ķ║¾Ų┌Ą─═┌Š“┼cøQ▓▀╠ß╣®▌oų·ų¦│ųĪŻ
ĪĪĪĪįńį┌┤¾öĄō■Ė┼─Ņ│÷¼Fų«Ū░Ż¼öĄō■╦▌į┤(Data Provenance)╝╝ągŠ═į┌öĄō■ÄņŅIė“Ą├ĄĮÅVĘ║蹊┐ĪŻŲõ╗∙▒Š│÷░l³c╩ŪÄ═ų·╚╦éā┤_Č©öĄō■é}ÄņųąĖ„ĒŚöĄō■Ą─üĒį┤Ż¼└²╚ń┴╦ĮŌ╦³éā╩Ūė╔──ą®▒ĒųąĄ───ą®öĄō■ĒŚ▀\╦ŃČ°│╔Ż¼ō■┤╦┐╔ęįĘĮ▒ŃĄž“×╦ŃĮY╣¹Ą─š²┤_ąįŻ¼╗“š▀ęįśOąĪĄ─┤·ār▀MąąöĄō■Ė³ą┬ĪŻöĄō■╦▌į┤Ą─╗∙▒ŠĘĮĘ©╩Ūś╦ėøĘ©Ż¼╚ńį┌┐┌╬─½Iųą═©▀^ī”öĄō■▀Mąąś╦ėøüĒėøõøöĄō■į┌öĄō■é}ÄņųąĄ─▓ķįā┼cé„▓źÜv╩ĘĪŻ║¾üĒĖ┼─Ņ▀Mę╗▓Į╝Ü╗»×ķwhy║═whereā╔ŅÉŻ¼Ęųäeé╚ųžöĄō■Ą─ėŗ╦ŃĘĮĘ©ęį╝░öĄō■Ą─│÷╠ÄĪŻ│²öĄō■Äņęį═ŌŻ¼╦³▀Ć░³└©XMLöĄō■Īó┴„öĄō■┼c▓╗┤_Č©öĄō■Ą─╦▌į┤╝╝ągĪŻ
ĪĪĪĪöĄō■╦▌į┤╝╝ągę▓┐╔ė├ė┌╬─╝■Ą─╦▌į┤┼c╗ųÅ═ĪŻ└²╚ń╬─½I═©▀^öUš╣Linuxā╚║╦┼c╬─╝■ŽĄĮyŻ¼äōĮ©┴╦ę╗éĆöĄō■Ųį┤┤µā”ŽĄĮyįŁą═ŽĄĮyŻ¼┐╔ęįūįäė╦č╝»Ųį┤öĄō■ĪŻ┤╦═Ōę▓ėąŲõį┌įŲ┤µā”ł÷Š░ųąĄ─æ¬ė├ĪŻ
ĪĪĪĪ╬┤üĒöĄō■╦▌į┤╝╝ągīóį┌ą┼Žó░▓╚½ŅIė“░lō]ųžę¬ū„ė├ĪŻį┌2009─Ļ│╩ł¾├└ć°ć°═┴░▓╚½▓┐Ą─“ć°╝ęŠWĮj┐šķg░▓╚½”Ą─ł¾ĖµųąŻ¼īóŲõ┴ą×ķ╬┤üĒ┤_▒Żć°╝ęĻPµI╗∙ĄAįO╩®░▓╚½Ą─3ĒŚĻPµI╝╝ągų«ę╗ĪŻ╚╗Č°Ż¼öĄō■╦▌į┤╝╝ągæ¬ė├ė┌┤¾öĄō■░▓╚½┼cļ[╦Į▒Żūoųą▀Ć├µI┼R╚ńŽ┬╠¶æŻ║
ĪĪĪĪ(1)öĄō■╦▌į┤┼cļ[╦Į▒Żūoų«ķgĄ─ŲĮ║ŌĪŻę╗ĘĮ├µŻ¼╗∙ė┌öĄō■╦▌į┤ī”┤¾öĄō■▀Mąą░▓╚½▒Żūo╩ūŽ╚ę¬═©▀^Ęų╬÷╝╝ąg½@Ą├┤¾öĄō■Ą─üĒį┤Ż¼╚╗▓┼─▄Ė³║├Ąžų¦│ų░▓╚½▓▀┬į║═░▓╚½ÖCųŲĄ─╣żū„Ż╗┴Ēę╗ĘĮ├µŻ¼öĄō■üĒį┤═∙═∙▒Š╔ĒŠ═╩Ūļ[╦Į├¶ĖąöĄō■ĪŻė├æ¶▓╗ŽŻ═¹▀@ĘĮ├µĄ─öĄō■▒╗Ęų╬÷š▀½@Ą├ĪŻę“┤╦Ż¼╚ń║╬ŲĮ║Ō▀@ā╔š▀Ą─ĻPŽĄ╩ŪųĄĄ├蹊┐Ą─å¢Ņ}ų«ę╗ĪŻ
ĪĪĪĪ(2)öĄō■╦▌į┤╝╝ągūį╔ĒĄ─░▓╚½ąį▒ŻūoĪŻ«öŪ░öĄō■╦▌į┤╝╝ąg▓óø]ėą│õĘų┐╝æ]░▓╚½å¢Ņ}Ż¼└²╚ńś╦ėøūį╔Ē╩Ūʱš²┤_Īóś╦ėøą┼Žó┼cöĄō■ā╚╚▌ų«ķg╩Ūʱ░▓╚½ĮēČ©Ą╚Ą╚ĪŻČ°į┌┤¾öĄō■ŁhŠ│Ž┬Ż¼Ųõ┤¾ęÄ─ŻĪóĖ▀╦┘ąįĪóČÓśėąįĄ╚╠ž³c╩╣įōå¢Ņ}Ė³╝ė═╗│÷ĪŻ
ĪĪĪĪ4.5 ĮŪ╔½═┌Š“
ĪĪĪĪ╗∙ė┌ĮŪ╔½Ą─įLå¢┐žųŲ(RBAC)╩Ū«öŪ░ÅVĘ║╩╣ė├Ą─ę╗ĘNįLå¢┐žųŲ─Żą═ĪŻ═©▀^×ķė├æ¶ųĖ┼╔ĮŪ╔½ĪóīóĮŪ╔½ĻP┬ōų┴ÖÓŽ▐╝»║ŽŻ¼īŹ¼Fė├æ¶╩┌ÖÓĪó║å╗»ÖÓŽ▐╣▄└ĒĪŻįńŲ┌Ą─RBACÖÓŽ▐╣▄└ĒČÓ▓╔ė├“ūįĒöŽ“Ž┬”Ą──Ż╩ĮŻ║╝┤Ė∙ō■Ų¾śIĄ─┬Ü╬╗įO┴óĮŪ╔½Ęų╣żĪŻ«öŲõæ¬ė├ė┌┤¾öĄō■ł÷Š░ĢrŻ¼├µ┼RąĶ┤¾┴┐╚╦╣żģó┼cĮŪ╔½äØĘųĪó╩┌ÖÓĄ─å¢Ņ}(ėųĘQ×ķĮŪ╔½╣ż│╠)ĪŻ
ĪĪĪĪ║¾üĒ蹊┐š▀éāķ_╩╝ĻPūó“ūįĄūŽ“╔Ž”─Ż╩ĮŻ¼╝┤Ė∙ō■¼Fėą“ė├æ¶ę╗ī”Ž¾”╩┌ÖÓŪķørŻ¼įOėŗ╦ŃĘ©ūįäėīŹ¼FĮŪ╔½Ą─╠ß╚Ī┼cā×╗»Ż¼ĘQ×ķĮŪ╔½═┌Š“ĪŻ║åå╬üĒšfŻ¼Š═╩Ū╚ń║╬įOų├║Ž└ĒĄ─ĮŪ╔½ĪŻĄõą═Ą─╣żū„░³└©Ż║ęį┐╔ęĢ╗»Ą─ą╬╩ĮŻ¼═©▀^ė├æ¶ÖÓŽ▐Č■ŠSłDĄ─┼┼ą“Üw▓óĄ─ĘĮ╩ĮīŹ¼FĮŪ╔½╠ß╚ĪŻ╗═©▀^ūė╝»├Č┼eęį╝░Š█ŅÉĄ─ĘĮĘ©╠ß╚ĪĮŪ╔½Ą╚ĘŪą╬╩Į╗»ĘĮĘ©Ż╗ę▓ėą╗∙ė┌ą╬╩Į╗»šZ┴xĘų╬÷Īó═©▀^īė┤╬╗»═┌Š“üĒĖ³£╩┤_╠ß╚ĪĮŪ╔½Ą─ĘĮĘ©ĪŻ
ĪĪĪĪ┐é¾wüĒšfŻ¼═┌Š“╔·│╔ūŅąĪĮŪ╔½╝»║ŽĄ─ūŅā×╦ŃĘ©ĢrķgÅ═ļsČ╚Ė▀Ż¼ČÓī┘ė┌NPę╗═Ļ╚½å¢Ņ}ĪŻę“Č°ę▓ėąčąŠ┐š▀ĻPūóį┌ČÓĒŚ╩ĮĢrķgā╚═Ļ│╔Ą─åó░l╩Į╦ŃĘ©ĪŻį┌┤¾öĄō■ł÷Š░Ž┬Ż¼▓╔ė├ĮŪ╔½═┌Š“╝╝ąg┐╔Ė∙ō■ė├æ¶Ą─įLå¢ėøõøūįäė╔·│╔ĮŪ╔½Ż¼Ė▀ą¦Ąž×ķ║Ż┴┐ė├æ¶╠ß╣®éĆąį╗»öĄō■Ę■äšĪŻ═¼Ģrę▓┐╔ė├ė┌╝░Ģr░l¼Fė├æ¶Ų½ļx╚š│Żąą×ķ╦∙ļ[▓žĄ─Øōį┌╬ŻļUĪŻĄ½«öŪ░ĮŪ╔½═┌Š“╝╝ąg┤¾Č╝╗∙ė┌Š½┤_ĪóĘŌķ]Ą─öĄō■╝»Ż¼į┌æ¬ė├ė┌┤¾öĄō■ł÷Š░Ģr▀ĆąĶę¬ĮŌøQöĄō■╝»äėæBūāĖ³ęį╝░┘|┴┐▓╗Ė▀Ą╚╠ž╩Ōå¢Ņ}ĪŻ
ĪĪĪĪ4.6 ’LļUūį▀mæ¬Ą─įLå¢┐žųŲ
ĪĪĪĪį┌┤¾öĄō■ł÷Š░ųąŻ¼░▓╚½╣▄└ĒåT┐╔─▄╚▒Ę”ūŃē“Ą─īŻśIų¬ūRŻ¼¤oĘ©£╩┤_Ąž×ķė├æ¶ųĖČ©Ųõ┐╔ęįįLå¢Ą─öĄō■ĪŻ’LļUūį▀mæ¬Ą─įLå¢┐žųŲ╩Ūßśī”▀@ĘNł÷Š░ėæšō▌^ČÓĄ─ę╗ĘNįLå¢┐žųŲĘĮĘ©ĪŻJasonĄ─ł¾Ėµ├Ķ╩÷┴╦’LļU┴┐╗»║═įLå¢┼õŅ~Ą─Ė┼─ŅĪŻļS║¾Ż¼ChengĄ╚╚╦╠ß│÷┴╦ę╗éĆ╗∙ė┌ČÓ╝ēäe░▓╚½─Żą═Ą─’LļUūį▀mæ¬įLå¢┐žųŲĮŌøQĘĮ░ĖĪŻNiĄ╚╚╦╠ß│÷┴╦┴Ēę╗éĆ╗∙ė┌─Ż║²═Ų└ĒĄ─ĮŌøQĘĮ░ĖŻ¼īóą┼ŽóĄ─öĄ─┐║═ė├æ¶ęį╝░ą┼ŽóĄ─░▓╚½Ą╚╝ēū„×ķ▀Mąą’LļU┴┐╗»Ą─ų„ę¬ģó┐╝ģóöĄĪŻ«öė├æ¶įLå¢Ą─┘Yį┤Ą─’LļUöĄųĄĖ▀ė┌─│éĆŅAČ©Ą─ķTŽ▐ĢrŻ¼ätŽ▐ųŲė├æ¶└^└mįLå¢ĪŻ╬─½I╠ß│÷┴╦ę╗ĘNßśī”ßt»¤öĄō■╠ß╣®ė├æ¶ļ[╦Į▒ŻūoĄ─┐╔┴┐╗»’LļUūį▀mæ¬įLå¢┐žųŲĪŻ═©▀^└¹ė├ĮyėŗīW║═ą┼ŽóšōĄ─ĘĮĘ©Ż¼Č©┴x┴╦┴┐╗»╦ŃĘ©Ż¼Å─Č°īŹ¼F╗∙ė┌’LļUĄ─įLå¢┐žųŲĪŻĄ½═¼ĢrŻ¼į┌┤¾öĄō■æ¬ė├ŁhŠ│ųąŻ¼’LļUĄ─Č©┴x║═┴┐╗»Č╝▌^ų«ęį═∙Ė³╝ė└¦ļyĪŻ
ĪĪĪĪ5.┤¾öĄō■Ę■äš┼cą┼Žó░▓╚½
ĪĪĪĪ5.1 ╗∙ė┌┤¾öĄō■Ą─═■├{░l¼F╝╝ąg
ĪĪĪĪė╔ė┌┤¾öĄō■Ęų╬÷╝╝ągĄ─│÷¼FŻ¼Ų¾śI┐╔ęį│¼įĮęį═∙Ą─“▒Żūo-Öz£y-Ēææ¬-╗ųÅ═”(PDRR)─Ż╩ĮŻ¼Ė³ų„äėĄž░l¼FØōį┌Ą─░▓╚½═■├{ĪŻ└²╚ńŻ¼IBM═Ų│÷┴╦├¹×ķIBM┤¾öĄō■░▓╚½ųŪ─▄Ą─ą┬ą═░▓╚½╣żŠ▀Ż¼┐╔ęį└¹ė├┤¾öĄō■üĒé╔£yüĒūįŲ¾śIā╚═Ō▓┐Ą─░▓╚½═■├{Ż¼░³└©Æ▀├ĶļŖūėÓ]╝■║═╔ńĮ╗ŠWĮjŻ¼ś╦╩Š│÷├„’@ą─┤µ▓╗ØMĄ─åT╣żŻ¼╠ßąčŲ¾śIūóęŌŻ¼ŅAĘ└Ųõą╣┬ČŲ¾śIÖC├▄ĪŻ“└ŌńR”ėŗäØę▓┐╔ęį▒╗└ĒĮŌ×ķæ¬ė├┤¾öĄō■ĘĮĘ©▀Mąą░▓╚½Ęų╬÷Ą─│╔╣”╣╩╩┬ĪŻ═©▀^╩š╝»Ė„éĆć°╝ęĖ„ĘNŅÉą═Ą─öĄō■Ż¼└¹ė├░▓╚½═■├{öĄō■║═░▓╚½Ęų╬÷ą╬│╔ŽĄĮyĘĮĘ©░l¼FØōį┌╬ŻļUŠųä▌Ż¼į┌╣źō¶░l╔·ų«Ū░ūRäe═■├{ĪŻŽÓ▒╚ė┌é„Įy╝╝ągĘĮ░ĖŻ¼╗∙ė┌┤¾öĄō■Ą─═■├{░l¼F╝╝ągŠ▀ėąęįŽ┬ā׳cĪŻ
ĪĪĪĪ(1)Ęų╬÷ā╚╚▌Ą─ĘČć·Ė³┤¾
ĪĪĪĪé„ĮyĄ─═■├{Ęų╬÷ų„ę¬ßśī”Ą─ā╚╚▌×ķĖ„ŅÉ░▓╚½╩┬╝■ĪŻČ°ę╗éĆŲ¾śIĄ─ą┼Žó┘Y«aät░³└©öĄō■┘Y«aĪó▄ø╝■┘Y«aĪóīŹ╬’┘Y«aĪó╚╦åT┘Y«aĪóĘ■äš┘Y«a║═Ųõ╦³×ķśIäš╠ß╣®ų¦│ųĄ─¤oą╬┘Y«aĪŻė╔ė┌é„Įy═■├{Öz£y╝╝ągĄ─ŠųŽ▐ąįŻ¼Ųõ▓ó▓╗─▄Ė▓╔w▀@┴∙ŅÉą┼Žó┘Y«aŻ¼ę“┤╦╦∙─▄░l¼FĄ─═■├{ę▓╩ŪėąŽ▐Ą─ĪŻČ°═©▀^į┌═■├{Öz£yĘĮ├µę²╚ļ┤¾öĄō■Ęų╬÷╝╝ągŻ¼┐╔ęįĖ³╚½├µĄž░l¼Fßśī”▀@ą®ą┼Žó┘Y«aĄ─╣źō¶ĪŻ└²╚ń═©▀^Ęų╬÷Ų¾śIåT╣żĄ─╝┤Ģr═©ą┼öĄō■ĪóEmailöĄō■Ą╚┐╔ęį╝░Ģr░l¼F╚╦åT┘Y«a╩Ūʱ├µ┼RŲõ╦³Ų¾śI“═┌ē”─_”Ą─╣źō¶═■├{ĪŻį┘▒╚╚ń═©▀^ī”Ų¾śIĄ─┐═æ¶▓┐ėåå╬öĄō■Ą─Ęų╬÷Ż¼ę▓─▄ē“░l¼Fę╗ą®«É│ŻĄ─▓┘ū„ąą×ķŻ¼▀MČ°┼ąöÓ╩Ūʱ╬Ż║”╣½╦Š└¹ęµĪŻ┐╔ęį┐┤│÷Ż¼Ęų╬÷ā╚╚▌ĘČć·Ą─öU┤¾╩╣Ą├╗∙ė┌┤¾öĄō■Ą─═■├{Öz£yĖ³╝ė╚½├µĪŻ
ĪĪĪĪ(2)Ęų╬÷ā╚╚▌Ą─Ģrķg┐ńČ╚Ė³ķL
ĪĪĪĪ¼FėąĄ─įSČÓ═■├{Ęų╬÷╝╝ągČ╝╩Ūā╚┤µĻP┬ōąįĄ─Ż¼ę▓Š═╩ŪšfīŹĢr╩š╝»öĄō■Ż¼▓╔ė├Ęų╬÷╝╝ąg░l¼F╣źō¶ĪŻĘų╬÷┤░┐┌═©│Ż╩▄Ž▐ė┌ā╚┤µ┤¾ąĪŻ¼¤oĘ©æ¬ī”│ų└mąį║═ØōĘ³ąį╣źō¶ĪŻČ°ę²╚ļ┤¾öĄō■Ęų╬÷╝╝ąg║¾Ż¼═■├{Ęų╬÷┤░┐┌┐╔ęįÖM┐ń╚¶Ė╔─ĻĄ─öĄō■Ż¼ę“┤╦═■├{░l¼F─▄┴”Ė³ÅŖŻ¼┐╔ęįėąą¦æ¬ī”APTŅÉ╣źō¶ĪŻ
ĪĪĪĪ(3)╣źō¶═■├{Ą─ŅA£yąį
ĪĪĪĪé„ĮyĄ─░▓╚½Ę└ūo╝╝ąg╗“╣żŠ▀┤¾ČÓ╩Ūį┌╣źō¶░l╔·║¾ī”╣źō¶ąą×ķ▀MąąĘų╬÷║═ÜwŅÉŻ¼▓óū÷│÷Ēææ¬ĪŻČ°╗∙ė┌┤¾öĄō■Ą─═■├{Ęų╬÷Ż¼┐╔▀Mąą│¼Ū░Ą─ŅA┼ąĪŻ╦³─▄ē“īżšęØōį┌Ą─░▓╚½═■├{Ż¼ī”╬┤░l╔·Ą─╣źō¶ąą×ķ▀MąąŅAĘ└ĪŻ
ĪĪĪĪ(4)ī”╬┤ų¬═■├{Ą─Öz£y
ĪĪĪĪé„ĮyĄ─═■├{Ęų╬÷═©│Ż╩Ūė╔Įø“מSĖ╗Ą─īŻśI╚╦åTĖ∙ō■Ų¾śIąĶŪ¾║═īŹļHŪķørš╣ķ_Ż¼╚╗Č°▀@ĘN═■├{Ęų╬÷Ą─ĮY╣¹║▄┤¾│╠Č╚╔Žę└┘ćė┌éĆ╚╦Įø“×ĪŻ═¼ĢrŻ¼Ęų╬÷╦∙░l¼FĄ─═■├{ę▓╩Ūęčų¬Ą─ĪŻČ°┤¾öĄō■Ęų╬÷Ą─╠ž³c╩Ūé╚ųžė┌Ųš═©Ą─ĻP┬ōĘų╬÷Ż¼Č°▓╗é╚ųžę“╣¹Ęų╬÷Ż¼ę“┤╦═©▀^▓╔ė├ŪĪ«öĄ─Ęų╬÷─Żą═Ż¼┐╔░l¼F╬┤ų¬═■├{ĪŻ
ĪĪĪĪļm╚╗╗∙ė┌┤¾öĄō■Ą─═■├{░l¼F╝╝ągŠ▀ėą╔Ž╩÷Ą─ā׳cŻ¼Ą½╩Ūįō╝╝ąg─┐Ū░ę▓┤µį┌ę╗ą®å¢Ņ}║═╠¶æŻ¼ų„ę¬╝»ųąį┌Ęų╬÷ĮY╣¹Ą─£╩┤_│╠Č╚╔ŽĪŻę╗ĘĮ├µŻ¼┤¾öĄō■Ą─╩š╝»║▄ļyū÷ĄĮ╚½├µŻ¼Č°öĄō■ėų╩ŪĘų╬÷Ą─╗∙ĄAŻ¼╦³Ą─Ų¼├µąį═∙═∙Ģ■ī¦ų┬Ęų╬÷│÷Ą─ĮY╣¹Ą─Ų½▓ŅĪŻ×ķ┴╦Ęų╬÷Ų¾śIą┼Žó┘Y«a├µ┼RĄ─═■├{Ż¼▓╗Ą½ę¬╚½├µ╩š╝»Ų¾śIā╚▓┐Ą─öĄō■Ż¼▀Ćę¬ī”ę╗ą®Ų¾śI═ŌĄ─öĄō■▀Mąą╩š╝»Ż¼▀@ą®į┌─│ĘN│╠Č╚╔Ž╩Ūę╗éĆ┤¾å¢Ņ}ĪŻ┴Ēę╗ĘĮ├µŻ¼┤¾öĄō■Ęų╬÷─▄┴”Ą─▓╗ūŃė░Ēæ═■├{Ęų╬÷Ą─£╩┤_ąįĪŻ└²╚ńŻ¼╝~╝s═Č┘YŃyąą├┐├ļĢ■ėą5000┤╬ŠWĮj╩┬╝■Ż¼├┐╠ņĢ■Å─ųą▓ČūĮ25TBöĄō■ĪŻ╚ń╣¹ø]ėąūŃē“Ą─Ęų╬÷─▄┴”Ż¼ę¬Å─╚ń┤╦²ŗ┤¾Ą─öĄō■ųą£╩┤_Ąž░l¼FśO╔┘öĄŅA╩ŠØōį┌╣źō¶Ą─╩┬╝■Ż¼▀MČ°Ęų╬÷│÷═■├{╩ŪÄū║§▓╗┐╔─▄═Ļ│╔Ą─╚╬äšĪŻ
ĪĪĪĪ5.2 ╗∙ė┌┤¾öĄō■Ą─šJūC╝╝ąg
ĪĪĪĪ╔ĒĘ▌šJūC╩Ūą┼ŽóŽĄĮy╗“ŠWĮjųą┤_šJ▓┘ū„š▀╔ĒĘ▌Ą─▀^│╠ĪŻé„ĮyĄ─šJūC╝╝ągų„ę¬═©▀^ė├æ¶╦∙ų¬Ą─├ž├▄Ż¼└²╚ń┐┌┴ŅŻ¼╗“š▀│ųėąĄ─æ{ūCŻ¼└²╚ńöĄūųūCĢ°Ż¼üĒĶbäeė├æ¶ĪŻ▀@ą®╝╝ąg├µ┼Rų°╚ńŽ┬ā╔éĆå¢Ņ}ĪŻ
ĪĪĪĪ╩ūŽ╚Ż¼╣źō¶š▀┐é╩Ū─▄ē“šęĄĮĘĮĘ©üĒ“_╚Īė├æ¶╦∙ų¬Ą─├ž├▄Ż¼╗“Ė`╚Īė├æ¶│ųėąĄ─æ{ūCŻ¼Å─Č°═©▀^šJūCÖCųŲĄ─šJūCĪŻ└²╚ń╣źō¶š▀└¹ė├ß׶~ŠWšŠĖ`╚Īė├æ¶┐┌┴ŅŻ¼╗“š▀═©▀^╔ńĢ■╣ż│╠īWĘĮ╩ĮĮėĮ³ė├æ¶Ż¼ų▒Įė“_╚Īė├æ¶╦∙ų¬├ž├▄╗“│ųėąĄ─æ{ūCĪŻ
ĪĪĪĪŲõ┤╬Ż¼é„ĮyšJūC╝╝ągųąšJūCĘĮ╩ĮįĮ░▓╚½═∙═∙ęŌ╬Čų°ė├涞ōō·įĮųžĪŻ└²╚ńŻ¼×ķ┴╦╝ėÅŖšJūC░▓╚½Ż¼Č°▓╔ė├Ą─ČÓę“╦žšJūCĪŻė├æ¶═∙═∙ąĶę¬═¼ĢrėøæøÅ═ļsĄ─┐┌┴ŅŻ¼▀Ćę¬ļS╔ĒöyĦė▓╝■USBKeyĪŻę╗Ą®═³ėø┐┌┴Ņ╗“š▀═³ėøöyĦUSBKeyŻ¼Š═¤oĘ©═Ļ│╔╔ĒĘ▌šJūCĪŻ×ķ┴╦£p▌pė├涞ōō·Ż¼ę╗ą®╔·╬’šJūCĘĮ╩Į│÷¼FŻ¼└¹ė├ė├涊▀ėąĄ─╔·╬’╠žš„Ż¼└²╚ńųĖ╝yĄ╚Ż¼üĒ┤_šJŲõ╔ĒĘ▌ĪŻ╚╗Č°Ż¼▀@ą®šJūC╝╝ągę¬Ū¾įOéõ▒žĒÜŠ▀ėą╔·╬’╠žš„ūRäe╣”─▄Ż¼└²╚ńųĖ╝yūRäeĪŻę“┤╦║▄┤¾│╠Č╚╔ŽŽ▐ųŲ┴╦▀@ą®šJūC╝╝ągĄ─ÅVĘ║æ¬ė├ĪŻ
ĪĪĪĪČ°į┌šJūC╝╝ągųąę²╚ļ┤¾öĄō■Ęų╬÷ät─▄ē“ėąą¦ĄžĮŌøQ▀@ā╔éĆå¢Ņ}ĪŻ╗∙ė┌┤¾öĄō■Ą─šJūC╝╝ągųĖĄ─╩Ū╩š╝»ė├æ¶ąą×ķ║═įOéõąą×ķöĄō■Ż¼▓óī”▀@ą®öĄō■▀MąąĘų╬÷Ż¼½@Ą├ė├æ¶ąą×ķ║═įOéõąą×ķĄ─╠žš„Ż¼▀MČ°═©▀^Ķbäe▓┘ū„š▀ąą×ķ╝░ŲõįOéõąą×ķüĒ┤_Č©Ųõ╔ĒĘ▌ĪŻ▀@┼cé„ĮyšJūC╝╝ąg└¹ė├ė├æ¶╦∙ų¬├ž├▄Ż¼╦∙│ųėąæ{ūCŻ¼╗“Š▀ėąĄ─╔·╬’╠žš„üĒ┤_šJŲõ╔ĒĘ▌ėą║▄┤¾▓╗═¼ĪŻŠ▀¾wĄžŻ¼▀@ĘNą┬Ą─šJūC╝╝ągŠ▀ėą╚ńŽ┬ā׳cĪŻ
ĪĪĪĪ(1)╣źō¶š▀║▄ļy─ŻöMė├æ¶ąą×ķ╠žš„üĒ═©▀^šJūCŻ¼ę“┤╦Ė³╝ė░▓╚½ĪŻ└¹ė├┤¾öĄō■╝╝ąg╦∙─▄╩š╝»Ą─ė├æ¶ąą×ķ║═įOéõąą×ķöĄō■╩ŪČÓśėĄ─Ż¼┐╔ęį░³└©ė├æ¶╩╣ė├ŽĄĮyĄ─ĢrķgĪóĮø│Ż▓╔ė├Ą─įOéõĪóįOéõ╦∙╠Ä╬’└Ē╬╗ų├Ż¼╔§ų┴╩Ūė├æ¶Ą─▓┘ū„┴ĢæTöĄō■ĪŻ═©▀^▀@ą®öĄō■Ą─Ęų╬÷─▄ē“×ķė├æ¶╣┤«ŗę╗éĆąą×ķ╠žš„Ą─▌å└¬ĪŻČ°╣źō¶š▀║▄ļyį┌ĘĮĘĮ├µ├µČ╝─ŻĘ┬ĄĮė├æ¶ąą×ķŻ¼ę“┤╦Ųõ┼cšµš²ė├æ¶Ą─ąą×ķ╠žš„▌å└¬▒ž╚╗┤µį┌ę╗éĆ▌^┤¾Ų½▓ŅŻ¼¤oĘ©═©▀^šJūCĪŻ
ĪĪĪĪ(2)£pąĪ┴╦ė├涞ōō·ĪŻė├æ¶ąą×ķ║═įOéõąą×ķ╠žš„öĄō■Ą─▓╔╝»Īó┤µā”║═Ęų╬÷Č╝ė╔šJūCŽĄĮy═Ļ│╔ĪŻŽÓ▒╚ė┌é„ĮyšJūC╝╝ągŻ¼śO┤¾Ąž£p▌p┴╦ė├涞ōō·ĪŻ
ĪĪĪĪ(3)┐╔ęįĖ³║├Ąžų¦│ųĖ„ŽĄĮyšJūCÖCųŲĄ─Įyę╗╗∙ė┌┤¾öĄō■Ą─šJūC╝╝ąg┐╔ęįūīė├æ¶į┌š¹éĆŠWĮj┐šķg▓╔ė├ŽÓ═¼Ą─ąą×ķ╠žš„▀Mąą╔ĒĘ▌šJūCŻ¼Č°▒▄├Ō▓╗═¼ŽĄĮy▓╔ė├▓╗═¼šJūCĘĮ╩ĮŻ¼Ūęė├æ¶╦∙ų¬├ž├▄╗“╦∙│ųėąæ{ūCę▓Ė„▓╗ŽÓ═¼Č°Ä¦üĒ┴╦ĘNĘN▓╗▒ŃĪŻ
ĪĪĪĪļm╚╗╗∙ė┌┤¾öĄō■Ą─šJūC╝╝ągŠ▀ėą╔Ž╩÷ā׳cŻ¼Ą½═¼Ģrę▓┤µį┌ę╗ą®å¢Ņ}║═╠¶æžĮ┤²ĮŌøQĪŻ
ĪĪĪĪ(1)│§╩╝ļAČ╬Ą─šJūCå¢Ņ}ĪŻ╗∙ė┌┤¾öĄō■Ą─šJūC╝╝ąg╩ŪĮ©┴óį┌┤¾┴┐ė├æ¶ąą×ķ║═įOéõąą×ķöĄō■Ęų╬÷Ą─╗∙ĄA╔ŽŻ¼Č°│§╩╝ļAČ╬▓╗Š▀éõ┤¾┴┐öĄō■ĪŻę“┤╦Ż¼¤oĘ©Ęų╬÷│÷ė├æ¶ąą×ķ╠žš„Ż¼╗“š▀Ęų╬÷Ą─ĮY╣¹▓╗ē“£╩┤_ĪŻ
ĪĪĪĪ(2)ė├æ¶ļ[╦Įå¢Ņ}ĪŻ╗∙ė┌┤¾öĄō■Ą─šJūC╝╝ąg×ķ┴╦─▄ē“½@Ą├ė├æ¶Ą─ąą×ķ┴ĢæTŻ¼▒ž╚╗ę¬ķLŲ┌│ų└mĄž╩š╝»┤¾┴┐Ą─ė├æ¶öĄō■ĪŻ─Ū├┤╚ń║╬į┌╩š╝»║═Ęų╬÷▀@ą®öĄō■Ą─═¼ĢrŻ¼┤_▒Żė├æ¶ļ[╦Įę▓╩ŪžĮ┤²ĮŌøQĄ─å¢Ņ}ĪŻ╦³╩Ūė░Ēæ▀@ĘNą┬Ą─šJūC╝╝ąg╩Ūʱ─▄ē“═ŲÅVĄ─ų„ę¬ę“╦žĪŻ
ĪĪĪĪ5.3 ╗∙ė┌┤¾öĄō■Ą─öĄō■šµīŹąįĘų╬÷
ĪĪĪĪ─┐Ū░Ż¼╗∙ė┌┤¾öĄō■Ą─öĄō■šµīŹąįĘų╬÷▒╗ÅVĘ║šJ×ķ╩ŪūŅ×ķėąą¦Ą─ĘĮĘ©ĪŻįSČÓŲ¾śIęčĮøķ_╩╝┴╦▀@ĘĮ├µĄ─蹊┐╣żū„Ż¼└²╚ńYahoo║═ThinkmailĄ╚└¹ė├┤¾öĄō■Ęų╬÷╝╝ągüĒ▀^×V└¼╗°Ó]╝■Ż╗YelpĄ╚╔ńĮ╗³cįuŠWĮjė├┤¾öĄō■Ęų╬÷üĒūRäe╠ō╝┘įušōŻ╗ą┬└╦╬ó▓®Ą╚╔ńĮ╗├Į¾w└¹ė├┤¾öĄō■Ęų╬÷üĒĶbäeĖ„ŅÉ└¼╗°ą┼ŽóĄ╚ĪŻ
ĪĪĪĪ╗∙ė┌┤¾öĄō■Ą─öĄō■šµīŹąįĘų╬÷╝╝ąg─▄ē“╠ßĖ▀└¼╗°ą┼ŽóĄ─Ķbäe─▄┴”ĪŻę╗ĘĮ├µŻ¼ę²╚ļ┤¾öĄō■Ęų╬÷┐╔ęį½@Ą├Ė³Ė▀Ą─ūRäe£╩┤_┬╩ĪŻ└²╚ńŻ¼ī”ė┌³cįuŠWšŠĄ─╠ō╝┘įušōŻ¼┐╔ęį═©▀^╩š╝»įušōš▀Ą─┤¾┴┐╬╗ų├ą┼ŽóĪóįušōā╚╚▌ĪóįušōĢrå¢Ą╚▀MąąĘų╬÷Ż¼ĶbäeŲõįušōĄ─┐╔┐┐ąįĪŻ╚ń╣¹─│įušōš▀×ķ─│ŲĘ┼ŲČÓéĆ═¼ŅÉ«aŲĘČ╝░l▒Ē┴╦É║ęŌįušōŻ¼ätŲõįušōĄ─šµīŹąįŠ═ųĄĄ├æčę╔Ż╗┴Ēę╗ĘĮ├µŻ¼į┌▀Mąą┤¾öĄō■Ęų╬÷ĢrŻ¼═©▀^ÖCŲ„īW┴Ģ╝╝ągŻ¼┐╔ęį░l¼FĖ³ČÓŠ▀ėąą┬╠žš„Ą─└¼╗°ą┼ŽóĪŻ╚╗Č°įō╝╝ąg╚į╚╗├µ┼Rę╗ą®└¦ļyŻ¼ų„ę¬╩Ū╠ō╝┘ą┼ŽóĄ─Č©┴xĪóĘų╬÷─Żą═Ą─śŗĮ©Ą╚ĪŻ
ĪĪĪĪ5.4 ┤¾öĄō■┼c“░▓╚½ę╗╝┤ę╗Ę■äš(Security-as-a-Service)”
ĪĪĪĪŪ░├µ┴ą┼e┴╦▓┐Ęų«öŪ░╗∙ė┌┤¾öĄō■Ą─ą┼Žó░▓╚½╝╝ągŻ¼╬┤üĒ▒žīóė┐¼F│÷Ė³ČÓĪóĖ³žSĖ╗Ą─░▓╚½æ¬ė├║═░▓╚½Ę■äšĪŻė╔ė┌┤╦ŅÉ╝╝ągęį┤¾öĄō■Ęų╬÷×ķ╗∙ĄAŻ¼ę“┤╦╚ń║╬╩š╝»Īó┤µā”║═╣▄└Ē┤¾öĄō■Š═╩ŪŽÓĻPŲ¾śI╗“ĮM┐Ś╦∙├µ┼RĄ─║╦ą─å¢Ņ}ĪŻ│²┴╦śO╔┘öĄŲ¾śIėą─▄┴”ū÷ĄĮų«═ŌŻ¼ī”ė┌Į^┤¾ČÓöĄą┼Žó░▓╚½Ų¾śIüĒšfŻ¼Ė³×ķ¼FīŹĄ─ĘĮ╩Į╩Ū═©▀^─│ĘNĘĮ╩Į½@Ą├┤¾öĄō■Ę■䚯¼ĮY║Žūį╝║Ą─╝╝ąg╠ž╔½ŅIė“Ż¼ī”═Ō╠ß╣®░▓╚½Ę■äšĪŻę╗ĘN╬┤üĒĄ─░lš╣Ū░Š░╩ŪŻ¼ęįĄūīė┤¾öĄō■Ę■äš×ķ╗∙ĄAŻ¼Ė„éĆŲ¾śIų«ķgĮM│╔ŽÓ╗źę└┘ćĪóŽÓ╗źų¦ō╬Ą─ą┼Žó░▓╚½Ę■äš¾wŽĄŻ¼┐é¾w╔Žą╬│╔ą┼Žó░▓╚½«aśIĮńĄ─┴╝║├╔·æBŁhŠ│ĪŻ
ĪĪĪĪ6.ąĪĮY
ĪĪĪĪ┤¾öĄō■ĦüĒ┴╦ą┬Ą─░▓╚½å¢Ņ}Ż¼Ą½╦³ūį╔Ēę▓╩ŪĮŌøQå¢Ņ}Ą─ųžę¬╩ųČ╬ĪŻ▒Š╬─Å─┤¾öĄō■Ą─ļ[╦Į▒ŻūoĪóą┼╚╬ĪóįLå¢┐žųŲĄ╚ĮŪČ╚│÷░lŻ¼╩ß└Ē┴╦«öŪ░┤¾öĄō■░▓╚½┼cļ[╦Į▒ŻūoŽÓĻPĻPµI╝╝ągĪŻĄ½┐é¾w╔ŽüĒšfŻ¼«öŪ░ć°ā╚═Ōßśī”┤¾öĄō■░▓╚½┼cļ[╦Į▒ŻūoĄ─ŽÓĻP蹊┐▀Ć▓╗│õĘųĪŻų╗ėą═©▀^╝╝ąg╩ųČ╬┼cŽÓĻPš■▓▀Ę©ęÄĄ╚ŽÓĮY║ŽŻ¼▓┼─▄Ė³║├ĄžĮŌøQ┤¾öĄō■░▓╚½┼cļ[╦Į▒Żūoå¢Ņ}ĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.lukmueng.com/
▒Š╬─ś╦Ņ}Ż║┤¾öĄō■░▓╚½┼cļ[╦Į▒Żūo
▒Š╬─ŠWųĘŻ║http://www.lukmueng.com/html/support/11121513093.html