ĪĪĪĪįŲ┤µā”╩Ūį┌įŲėŗ╦Ń(Cloud Computing)Ė┼─Ņ╔Žčė╔ņ║═░lš╣│÷üĒĄ─ę╗éĆą┬Ą─Ė┼─ŅŻ¼╩ŪųĖ═©▀^╝»╚║æ¬ė├ĪóŠWĖ±╝╝ąg╗“Ęų▓╝╩Į╬─╝■ŽĄĮyĄ╚╣”─▄Ż¼īóŠWĮjųą┤¾┴┐Ė„ĘN▓╗═¼ŅÉą═Ą─┤µā”įOéõ═©▀^æ¬ė├▄ø╝■╝»║ŽŲüĒģf═¼╣żū„Ż¼ģf═¼ī”═Ō╠ß╣®öĄō■┤µā”║═śIäšįLå¢╣”─▄Ą─ę╗éĆŽĄĮyĪŻĘų▓╝╩Į╬─╝■ŽĄĮy╩Ū│ŻęÄĄ─ĘųĢrŽĄĮyųą╬─╝■ŽĄĮyĄ─Ęų▓╝╩ĮīŹ¼FŻ¼ų¦│ų╬’└Ē╔ŽĘų╔óĄ─ČÓéĆė├æ¶╣▓ŽĒ╬─╝■║═┤µā”öĄō■ĪŻ╦³░³║¼ā╔éĆĘĮ├µĄ─║¼┴xŻ¼Å─┐═æ¶╩╣ė├Ą─ĮŪČ╚üĒ┐┤Ż¼╦³╩Ūę╗éĆś╦£╩Ą─╬─╝■ŽĄĮyŻ¼╠ß╣®┴╦ę╗ŽĄ┴ąAPIŻ¼ė╔┤╦▀Mąą╬─╝■╗“─┐õøĄ─äōĮ©ĪóęŲäėĪóäh│²ęį╝░ī”╬─╝■Ą─ūxīæĄ╚▓┘ū„ĪŻÅ─ā╚▓┐īŹ¼FüĒ┐┤Ż¼Ęų▓╝╩ĮĄ─ŽĄĮyät▓╗į┘║═Ųš═©╬─╝■ŽĄĮyę╗śėžōž¤╣▄└Ē▒ŠĄž┤┼▒PŻ¼╦³Ą─╬─╝■ā╚╚▌║═─┐õøĮYśŗČ╝▓╗╩Ū┤µā”į┌▒ŠĄž┤┼▒P╔ŽŻ¼Č°╩Ū═©▀^ŠWĮjé„▌öĄĮ▀hČ╦ŽĄĮy╔ŽĪŻ▓óŪęŻ¼═¼ę╗éĆ╬─╝■┤µā”▓╗ų╗╩Ūį┌ę╗┼_ÖCŲ„╔ŽŻ¼Č°╩Ūį┌ę╗┤žÖCŲ„╔ŽĘų▓╝╩Į┤µā”Ż¼ģf═¼╠ß╣®Ę■äšĪŻ
ĪĪĪĪĘų▓╝╩Į╬─╝■ŽĄĮy╩Ūę╗éĆ▒╚▌^╗Ņ▄SĄ─蹊┐ĘĮŽ“Ż¼ć°ā╚═Ō║▄ČÓ┤¾īWĪó蹊┐ÖCśŗ║═Ų¾śIų°╩ųķ_░lūį╝║Ą─Ęų▓╝╩Į╬─╝■ŽĄĮyŻ¼╚ńųą┐Ųį║ėŗ╦Ń╦∙Ą─╦{÷LĘų▓╝╩Į╬─╝■ŽĄĮy(BWFS)ĪóļŖūė┐Ų╝╝┤¾īWĄ─Ęų▓╝╩Į╬─╝■ŽĄĮy(DPFS)ĪóIBMĄ─GPFSĪóSunĄ─LustreĄ╚Ż¼▀@ą®ŽĄĮyų¦│ųI/O├▄╝»ą═æ¬ė├Ż¼═©│Żė├ė┌Ė▀ąį─▄ėŗ╦Ń╗“┤¾ą═öĄō■ųąą─Ż¼ī”ė▓╝■įO╩®ę¬Ū¾▌^Ė▀Ż╗GoogleĄ─GFS╝░Ųõķ_į┤īŹ¼FHDFS═©│Żė├ė┌╠ß╣®║Ż┴┐öĄō■Ą─┤µā”║═įLå¢─▄┴”Ż╗▀Ćėąę╗ą®│Żė├Ą─▒╚▌^▌p┴┐╝ēĄ─Ęų▓╝╩Į╬─╝■ŽĄĮyŻ¼╚ńMogileFS║═FastDFSų„ę¬ė├ė┌┤µā”Webæ¬ė├Ą─┘Yį┤╬─╝■ĪŻĄ½═¼Ģrę▓┤µį┌ę╗ą®å¢Ņ}ąĶę¬▀Mę╗▓Į蹊┐Ż¼╚ńHDFS║═MooseFS┤µį┌å╬į¬öĄō■Ę■äšŲ„ę└┘ćŻ¼╚ń║╬Ė─▀Mį¬öĄō■╣▄└ĒŽĄĮy╗“š▀į÷╝ėį¬öĄō■╣▄└ĒĘ■äšŲ„Ż╗MogileFS║═FastDFSĄ─╣▄└Ē╣سc░³║¼ČÓéĆš{Č╚Ę■äšŲ„Ż¼╚ń║╬╩╣ČÓéĆš{Č╚Ę■äšŲ„▀_ĄĮžō▌dŠ∙║ŌŻ╗GFS║═Lustre═©▀^µiĘ■äšüĒ▒ŻūCöĄō■ę╗ų┬ąįŻ¼Ą½═¼ę╗Ģrķg▓╗į╩įSČÓéĆė├æ¶ī”╬─╝■Ą─═¼ę╗▓┐Ęų▀Mąąīæ▓┘ū„Ż╗Ęų▓╝╩Į╬─╝■ŽĄĮyĄ─┐╔┐┐ąįę▓╩Ūę╗éĆ┤¾å¢Ņ}Ż¼¼FėąĄ─╚▌ÕeÖCųŲ═©▀^éõĘ▌╚šųŠ╗ųÅ═į¬öĄō■╣▄└ĒĘ■äšŲ„Ż¼į÷╝ėéõė├į¬öĄō■╣▄└ĒĘ■äšŲ„Ż¼▓╔ė├┤┼▒PĻć┴ąęį╝░éõĘ▌╬─╝■Ą╚Ż¼Č╝ėąę╗Č©Ą─ŠųŽ▐ąįĪŻīóüĒŻ¼═©ė├Ęų▓╝╩Į╬─╝■ŽĄĮy║═īŻė├Ęų▓╝╩Į╬─╝■ŽĄĮyĄ─Ęų╣żīóįĮüĒįĮ├„’@Ż¼═©ė├Ęų▓╝╩Į╬─╝■ŽĄĮy╠ß╣®ś╦£╩APIĮė┐┌Ż¼▓╗ąĶę¬ķ_░lš▀ą▐Ė─╔Žīėæ¬ė├Š═─▄╩╣ė├Ż¼Č°Ūęų¦│ųė├æ¶┐šķg╬─╝■ŽĄĮy(Filesystem in UserspaceŻ¼FUSE)Ż¼ė├æ¶╣▄└Ē╣▓ŽĒĄ─Ęų▓╝╩Į╬─╝■ŽĄĮy╚ń═¼╣▄└Ē▒ŠĄž╬─╝■ŽĄĮyę╗śėĘĮ▒ŃŻ¼▀ĆīóŽ“┤¾ą═╗»░lš╣Ż¼╠ß╣®Ė³┴«ārĄ─┤µā”Ę■䚯¼įŲ┤µā”Š═╩Ūę╗éĆ║▄║├Ą─┤·▒ĒŻ╗┼c┤╦ŽÓĘ┤Ż¼īŻė├Ęų▓╝╩Į╬─╝■ŽĄĮy╠ß╣®īŻėąAPIŻ¼ī”ķ_░lš▀ę¬Ū¾╩ņŽżšŲ╬šŲõAPIŻ¼Ą½ŲõŽĄĮyÅ═ļsČ╚▌^Ą═Ż¼Č°Ūę╠ß╣®▌^Ė▀Ą─ąį─▄Ż¼į┌Webæ¬ė├ĪóĖ▀ąį─▄ėŗ╦ŃĄ╚ĘĮ├µėą▌^┤¾Ą─ąĶŪ¾Ż¼▀@ā╔ĘNĘų▓╝╩Į╬─╝■ŽĄĮy╩Ū╬┤üĒĄ─░lš╣┌ģä▌ĪŻķ_į┤╔ńģ^ę▓ķ_░l│÷┴╦ę╗┼·╗∙ė┌Linux/Unix▓┘ū„ŽĄĮyĄ─Ęų▓╝╩Į╬─╝■ŽĄĮyŻ¼š²╩Ū▀@ą®ķ_į┤ĒŚ─┐┤¾┤¾┤┘▀M┴╦Ęų▓╝╩Į╬─╝■ŽĄĮyĄ─░lš╣║═æ¬ė├ĪŻ
ĪĪĪĪ1ĪóĘų▓╝╩Į╬─╝■ŽĄĮy
ĪĪĪĪĘų▓╝╩Į╬─╝■ŽĄĮy╩ŪųĖ╬─╝■ŽĄĮy╣▄└ĒĄ─╬’└Ē┤µā”┘Yį┤▓╗ę╗Č©ų▒Įė┤µā”į┌▒ŠĄž╣سc╔ŽŻ¼Č°╩Ū═©▀^ėŗ╦ŃÖCŠWĮj┼c╣سcŽÓ▀BŻ¼ų¦│ųČÓéĆė├æ¶╣▓ŽĒ╬─╝■║═┤µā”┘Yį┤ĪŻ┐╔ęįĘų×ķ═©ė├Ęų▓╝╩Į╬─╝■ŽĄĮy║═īŻśIĘų▓╝╩Į╬─╝■ŽĄĮyŻ¼ŽÓ▒╚ŲüĒ═©ė├Ęų▓╝╩Į╬─╝■ŽĄĮyī”ķ_░lš▀üĒšfŠ▀ėąėč║├ąįÅŖĄ─ā×ä▌Ż¼ŽĄĮyÅ═ļsąįŽÓī”▌^Ė▀Ż¼ąį─▄ę╗░ŃŻ╗Č°īŻė├Ęų▓╝╩Į╬─╝■ŽĄĮyĄ─ķ_░lš▀ėč║├ąį▌^▓ŅŻ¼ŽĄĮyÅ═ļsąį▌^Ą═Ż¼ąį─▄▌^Ė▀ĪŻę“┤╦Ż¼Ė∙ō■īŻė├ąį║══©ė├ąįĄ─įŁätŻ¼į┌▀xō±Ęų▓╝╩ĮŽĄĮyĄ─Ģr║“ąĶę¬┐╝æ]ėąĻPĘų▓╝╩ĮŽĄĮyĄ─æ¬ė├ŁhŠ│ĪŻ
ĪĪĪĪ1.1 HDFSĘų▓╝╩Į╬─╝■ŽĄĮy
ĪĪĪĪHDFS╩Ūę╗ĘN╗∙ė┌JavaĄ─▀mė├ė┌║Ż┴┐öĄō■┤µā”Ą─ķ_į┤Ęų▓╝╩Į╬─╝■ŽĄĮyĪŻ╦³┐╔ęį▓┐╩į┌Ą═│╔▒ŠĄ─ė▓╝■╔ŽŻ¼─▄ē“Ė▀╚▌ÕeĪó┐╔┐┐Ąž┤µā”PB╝ēĄ─öĄō■Ż¼▀Ć┐╔ęį┼cMapReduceŠÄ│╠─Żą═║▄║├ĄžĮY║ŽŻ¼×ķæ¬ė├│╠ą“╠ß╣®Ė▀═╠═┬┴┐Ą─öĄō■įLå¢ĪŻHDFSĄ─╝▄śŗ╚ńłD1╦∙╩ŠĪŻ
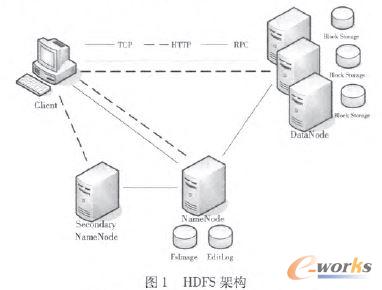
ĪĪĪĪHDFSų„ę¬ė├ė┌▒Ż┤µ┤¾╬─╝■Ż¼ė├æ¶═©▀^APIįLå¢╬─╝■ŽĄĮyĪŻ┤µā”╬─╝■ĢrŻ¼├┐éĆ╬─╝■▒╗Ęų│╔╚¶Ė╔éĆöĄō■ēKŻ¼ēK┤¾ąĪ─¼šJ╩Ū64MBŻ¼Ž╚░čöĄō■ēKŠÅ┤µį┌▒ŠĄžŻ¼┤¾ąĪ└█ĘeĄĮ64MBĢr▓┼┬ōŽĄNameNodeŻ¼īæ╚╦ĄĮDataNodeŻ¼═¼ĢrŻ¼į┌Ųõ╦¹╣سc▓╔ė├┴„╦«ŠĆĘĮ╩ĮéõĘ▌╬─╝■Ż¼─¼šJ╩Ū3Ę▌ĪŻ╬─╝■äh│²ĢrŻ¼ęŲäėĄĮ╗ž╩ššŠŻ¼į┌┼õų├Ą─Ģrķgā╚┐╔ęįčĖ╦┘╗ųÅ═ĪŻHDFS╠ß│÷Ą─ūįäėŠ∙║ŌĘĮ░ĖŻ¼┐╔ęįūįäėĄžīóöĄō■Å─ę╗éĆöĄō■╣سcęŲäėĄĮ┐šķeĄ─öĄō■╣سcĪŻČ°ŪęŻ¼HDFS╠ß╣®Ą─Įė┐┌┐╔ęį║▄╚▌ęūĄžīóöĄō■Å─ę╗éĆŲĮ┼_ęŲäėĄĮ┴Ē═Ōę╗éĆŲĮ┼_ĪŻ
ĪĪĪĪHDFSų╗ėąå╬éĆ╣▄└ĒĘ■äšŲ„Ż¼╦∙ėąī”╬─╝■Ą─šłŪ¾Č╝ę¬Įø▀^╦³Ż¼«öšłŪ¾▀^ČÓĢrŻ¼┐ŽČ©Ģ■ėąčėĢrŻ¼╦∙ęįHDFS▓╗╠½▀m║Žė┌─Ūą®ę¬Ū¾Ą═čėĢrįLå¢Ą─æ¬ė├│╠ą“ĪŻ
ĪĪĪĪė╔ė┌╣▄└ĒĘ■äšŲ„░č╬─╝■ŽĄĮyĄ─į¬öĄō■Ę┼ų├į┌ā╚┤µųąŻ¼╬─╝■ŽĄĮy╦∙─▄╚▌╝{Ą─╬─╝■öĄ─┐╩Ūė╔╣▄└ĒĘ■äšŲ„Ą─ā╚┤µ┤¾ąĪüĒøQČ©Ż¼╦∙ęįHDFS▓╗╠½▀m║Ž╠Ä└Ē┤¾┴┐ąĪ╬─╝■ĪŻČ°ŪęHadoopų╗ų¦│ųå╬ė├æ¶īæŻ¼▓╗ų¦│ų▓ó░lČÓė├æ¶īæĪŻ
ĪĪĪĪ1.2 LustreĘų▓╝╩Į╬─╝■ŽĄĮy
ĪĪĪĪLustre╩Ū╩ūéĆ╗∙ė┌ī”Ž¾┤µā”Ą─ķ_į┤Ęų▓╝╩Į╬─╝■ŽĄĮyŻ¼ė├üĒĮŌøQ║Ż┴┐┤µā”å¢Ņ}Ż¼ūŅČÓ┐╔ų¦│ų10000éĆ┐═æ¶Č╦Ż¼PB╝ēĄ─┤µā”┴┐Ż¼IOOGB/SĄ─é„▌ö╦┘Č╚Ż¼Š▀ėą═Ļ├└Ą─░▓╚½ąį║═┐╔╣▄└ĒąįĪŻLustre╬─╝■ŽĄĮyę╗░Ń▀\ąąį┌Ė▀ąį─▄ėŗ╦ŃÖCŽĄĮyų«╔ŽŻ¼Ųõąį─▄ā×įĮŻ¼▒╗įĮüĒįĮÅVĘ║Ąžæ¬ė├ĪŻLustre╝▄śŗ╚ńłD2╦∙╩ŠĪŻ
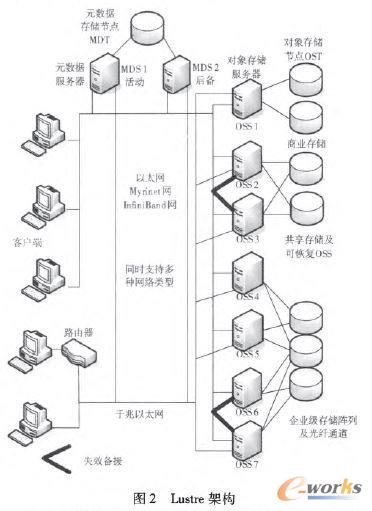
ĪĪĪĪLustre╩Ūę╗éĆ╚½Šų╬─╝■ŽĄĮyŻ¼ė├æ¶įLå¢╬─╝■ŽĄĮyĄ─╬─╝■öĄō■ĢrŻ¼═©▀^┐═æ¶Č╦╠ß╣®Ą─ś╦£╩POSIX(Portable Operating System InterfaceŻ¼┐╔ęŲų▓▓┘ū„ŽĄĮyĮė┐┌)Įė┐┌Ž╚įLå¢MDSŻ¼½@╚ĪŽÓĻPĄ─į¬öĄō■ą┼ŽóŻ¼╚╗║¾ų▒Įė┼cŽÓæ¬Ą─OSS═©ą┼Ż¼╚ĪĄ├╬─╝■Ą─īŹļHöĄō■Ż¼▀@║═HDFSĘŪ│ŻŽÓ╦ŲĪŻOST╔ŽĄ─╬─╝■öĄō■╩ŪęįĘųŚlą╬╩Į▒Ż┤µĄ─Ż¼▀@║═é„ĮyĄ─╗∙ė┌ēKĄ─┤µā”ĘĮ╩Įėą╦∙▓╗═¼ĪŻį┌Lustre╬─╝■ŽĄĮyųąŻ¼MDS┐╔ęįėąā╔éĆŻ¼▓╔ė├Active StandBy╚▌ÕeĘĮ╩ĮŻ¼«öę╗éĆMDS▓╗─▄š²│Ż╣żū„ĢrŻ¼┴Ē═Ōę╗éĆMDSåóäėĘ■äšĪŻLustre▀ĆīŹ¼F┴╦▓┐Ęų╬─╝■µiŻ¼┐╔ęį╩╣ČÓéĆ┐═æ¶Č╦į┌═¼ę╗Ģrķgīæ═¼ę╗╬─╝■Ą─▓╗═¼ģ^ė“Ż¼śO┤¾Ąž╠ßĖ▀┴╦ČÓė├æ¶ī”═¼ę╗╬─╝■▓ó░lįLå¢ĢrŽĄĮyĄ─ąį─▄ĪŻ
ĪĪĪĪLustre╬─╝■ŽĄĮyĄ─ąį─▄║═┐╔öUš╣ąįČ╝▓╗ÕeŻ¼Ą½ė▓╝■įOéõę¬Ū¾▒╚▌^Ė▀Ż¼Č°ŪęLustre─┐Ū░▀Ćø]īŹ¼FMDS╝»╚║╣▄└ĒŻ¼ļm╚╗ŽÓ▒╚ė┌HDFSĄ─å╬ų„╣سcŻ¼LustreĄ─ļpMDSį┌┐╔ė├ąį╔Ž╠ßĖ▀┴╦▓╗╔┘Ż¼Ą½«öŽĄĮy▀_ĄĮę╗Č©ęÄ─ŻĢrŻ¼MDSĢ■│╔×ķLustreŽĄĮyĄ─Ų┐ŅiĪŻ
ĪĪĪĪ1.3 FastDFSĘų▓╝╩Į╬─╝■ŽĄĮy
ĪĪĪĪFastDFS╩Ūę╗éĆ▌p┴┐╝ēĄ─ķ_į┤Ęų▓╝╩Į╬─╝■ŽĄĮyŻ¼ų„ę¬ė├üĒĮŌøQ┤¾╚▌┴┐Ą─╬─╝■┤µā”║═Ė▀▓ó░lįLå¢Ą─å¢Ņ}Ż¼╠žäe▀m║Ž┤¾ųąą═ŠWšŠ╩╣ė├Ż¼ė├üĒ┤µā”┘Yį┤╬─╝■Ż¼╚ńłDŲ¼Īó╬─ÖnĪóę¶ŅlĪóęĢŅlĄ╚ĪŻFastDFS▓╔ė├┴╦ĘųĮM┤µā”ĘĮ╩ĮŻ¼ę╗éĆĮMė╔ČÓ┼_┤µā”Ę■äšŲ„ĮM│╔Ż¼═¼ĮM┤µā”Ę■äšŲ„╔ŽĄ─╬─╝■╩Ū═Ļ╚½ę╗ų┬Ą─Ż¼╬─╝■╔Žé„Īóäh│²Ą╚▓┘ū„┐╔ęįį┌╚╬ęŌę╗┼_Storage Server╔Ž▀MąąŻ¼═¼ĮMā╚Ą─Storage Serverų«ķg▓╔ė├═Ų╦═╝╝ągPUSHĘĮ╩Į▀Mąą═¼▓ĮĪŻ
ĪĪĪĪTracker Serverį┌ā╚┤µųąėøõøĘųĮM║═Storage ServerĄ─ĀŅæBĄ╚ą┼ŽóŻ¼▓╗ėøõø╬─╝■╦„ę²ą┼ŽóŻ¼š╝ė├Ą─ā╚┤µ┴┐║▄╔┘ĪŻFastDFS▓╗ī”╬─╝■▀MąąĘųēK┤µā”Ż¼Ė³╝ė║åØŹĖ▀ą¦Ż¼▓óŪę═Ļ╚½─▄ØMūŃĮ^┤¾ČÓöĄ╗ź┬ōŠWæ¬ė├Ą─īŹļHąĶę¬ĪŻFastDFS░č║åØŹ║═Ė▀ą¦ū÷ĄĮ┴╦śOų┬Ż¼▒╚╚ńę╗éĆĘųĮMĄ─┤µā”Ę■äšŲ„įLå¢ē║┴”▌^┤¾ĢrŻ¼┐╔ęįį┌įōĮMį÷╝ė┤µā”Ę■äšŲ„üĒöU│õĘ■äš─▄┴”ĪŻ«öŽĄĮy╚▌┴┐▓╗ūŃĢrŻ¼┐╔ęįį÷╝ėĮMüĒöU│õ┤µā”╚▌┴┐ĪŻė╔ė┌═¼ĮMĄ─Storage Server╔ŽĄ─╬─╝■╩Ū═Ļ╚½ę╗ų┬Ą─Ż¼╦∙ęįę╗éĆĮMĄ─┤µā”╚▌┴┐×ķįōĮMā╚┤µā”Ę■äšŲ„╚▌┴┐ūŅąĪĄ──ŪéĆĪŻ
ĪĪĪĪ1.4 MogileFSĘų▓╝╩Į╬─╝■ŽĄĮy
ĪĪĪĪMogileFS╩Ūę╗éĆķ_į┤Ą─Ęų▓╝╩Į╬─╝■ŽĄĮyŻ¼┐╔ų¦│ų╬─╝■ūįäėéõĘ▌Ą─╣”─▄Ż¼╠ß╣®Ė▀┐╔ė├ąį║═Ė▀┐╔öUš╣ąįŻ¼▀m║Ž┤µā”ņoæB╬─╝■Ż¼Š═╩Ūę╗┤╬▒Ż┤µŻ¼ČÓ┤╬ūx╚ĪĄ─┘Yį┤ĪŻMogileFSŽĄĮyĄ─ĮM╝■Č╝┐╔ęį▀\ąąį┌ČÓéĆÖCŲ„╔ŽŻ¼╦∙ęį▓╗┤µį┌å╬³c╩¦öĪĪŻMogileFS┐╔ęįĖ∙ō■▓╗═¼Ą─╬─╝■ŅÉą═Ż¼Å═ųŲØMūŃ▀@éĆŅÉäeĄ─ūŅ╔┘ę¬Ū¾Ż¼╚ń╣¹öĄō■üG╩¦┴╦Ż¼┐╔ęįųžą┬Į©┴ó▀z╩¦Ą─┐ĮžÉöĄŻ¼▀@śė┐╔ęį╣Ø╝s┤┼▒PĪŻMogileFS╠ß╣®╚½ŠųĄ─├³├¹┐šķgŻ¼╬─╝■═©▀^ĮoČ©Ą─KeyüĒ┤_Č©Ż¼┐═æ¶Č╦═©▀^īŻėąAPIįLå¢MogileFSŽĄĮyŻ¼ī”š¹éĆ╬─╝■ŽĄĮy▀Mąąūxīæ▓┘ū„ĪŻ
ĪĪĪĪė╔ė┌MogileFSŽĄĮy▓╗ų¦│ųī”ę╗éĆ╬─╝■Ą─ļSÖCūxīæŻ¼ę“┤╦ų╗▀m║Žū÷ę╗▓┐Ęųæ¬ė├Ż¼╚ńłDŲ¼╬─╝■Ż¼ņoæBHTML╬─╝■Ż¼ų╗╠ß╣®Ž┬▌dĄ─╬─╝■Ż¼╝┤╬─╝■īæ╚ļ║¾╗∙▒Š╔Ž▓╗ąĶꬹ▐Ė─Ą─æ¬ė├Ż¼«ö╚╗ę▓┐╔ęį╔·│╔ę╗éĆą┬Ą─╬─╝■Ė▓╔wįŁ╬─╝■ĪŻ
ĪĪĪĪ1.5 MooseFSĘų▓╝╩Į╬─╝■ŽĄĮy
ĪĪĪĪMooseFS╩Ūę╗éĆŠ▀ėą╚▌Õe╣”─▄Ą─Ż¼Ė▀┐╔ė├Īó┐╔öUš╣Ą─║Ż┴┐╝ēĘų▓╝╩Į╬─╝■ŽĄĮyĪŻMooseFSĘų▓╝╩Į╬─╝■ŽĄĮyų¦│ųFUSEŻ¼┐═æ¶Č╦═©▀^FUSEā╚║╦Įė┐┌ÆņĮė▀h│╠╣▄└ĒĘ■äšŲ„╔Ž╦∙╣▄└ĒĄ─öĄō■┤µā”Ę■äšŲ„Ż¼╣▄└Ē╣▓ŽĒĄ─╬─╝■ŽĄĮy╚ń═¼╣▄└Ē▒ŠĄž╬─╝■ŽĄĮyę╗śėĪŻMooseFS┐╔äėæBļSĢrį÷╝ėÖCŲ„╗“š▀┤┼▒PŻ¼╠ß╣®╗ž╩ššŠ╣”─▄Ż¼┐╔╗ž╩šį┌ųĖČ©Ģrķgā╚äh│²Ą─╬─╝■Ż¼▀Ć┐╔ęįī”š¹éĆ╬─╝■╔§ų┴š²į┌īæ╚ļĄ─╬─╝■äōĮ©╬─╝■Ą─┐ņššĪŻ
ĪĪĪĪMooseFS░č╬─╝■ŽĄĮyĄ─ĮYśŗŠÅ┤µĄĮMasterĄ─ā╚┤µųąŻ¼╬─╝■įĮČÓŻ¼MasterĄ─ā╚┤µŽ¹║─įĮ┤¾ĪŻ«öį¬öĄō■Ę■äšŲ„öĄō■üG╩¦╗“š▀ōpܦĢrŻ¼┐╔Å─╚šųŠĘ■äšŲ„╗ųÅ═ĪŻ┼cMogileFSŽÓ▒╚Ż¼īæ▓┘ū„ĢrŻ¼═¼śėéõĘ▌öĄĄ─ŪķørŽ┬Ż¼MooseFSę¬┬²▌^ČÓĪŻūx▓┘ū„ĢrŻ¼«ö▓ó░l╝ė┤¾ĢrŻ¼šłŪ¾Ą─│╔╣”┬╩MooseFS▒╚MogileFSꬥ═Ż¼MooseFSĄ─Ę┤æ¬Ģrķgę▓▒╚MogileFSę¬┬²║▄ČÓĪŻ
ĪĪĪĪ2ĪóĖ─▀MĄ─HDFS
ĪĪĪĪ2.1 HDFS┤µį┌Ą─å¢Ņ}
ĪĪĪĪę“×ķNamenode░č╬─╝■ŽĄĮyĄ─į¬öĄō■Ę┼ų├į┌ā╚┤µųąŻ¼╦∙ęį╬─╝■ŽĄĮy╦∙─▄╚▌╝{Ą─╬─╝■öĄ─┐╩Ūė╔Name.NodeĄ─ā╚┤µ┤¾ąĪüĒøQČ©ĪŻę╗░ŃüĒšfŻ¼├┐ę╗éĆ╬─╝■Īó╬─╝■ŖA║═BlockąĶ꬚╝ō■150byteū¾ėęĄ─┐šķgŻ¼╦∙ęįŻ¼╚ń╣¹ėą100╚féĆ╬─╝■Ż¼├┐ę╗éĆš╝ō■ę╗éĆBlockŻ¼Š═ų┴╔┘ąĶę¬300MBā╚┤µŻ╗«ööUš╣ĄĮöĄ╩«ā|ĢrŻ¼ī”ė┌«öŪ░Ą─ė▓╝■╦«ŲĮüĒšfŠ═ø]Ę©īŹ¼F┴╦Ż¼▀@śėNameNodeā╚┤µ╚▌┴┐ć└ųžųŲ╝s┴╦╝»╚║Ą─öUš╣ĪŻHDFSūŅ│§╩Ū×ķ┴„╩ĮįLå¢┤¾╬─╝■ķ_░lĄ─Ż¼╚ń╣¹įLå¢┤¾┴┐ąĪ╬─╝■Ż¼ąĶę¬▓╗öÓÅ─ę╗éĆDataNode╠°ĄĮ┴Ēę╗éĆDataNodeŻ¼╠Ä└Ē┤¾┴┐ąĪ╬─╝■╦┘Č╚▀h▀hąĪė┌╠Ä└Ē═¼Ą╚┤¾ąĪĄ─┤¾╬─╝■Ą─╦┘Č╚Ż¼ć└ųžė░Ēæąį─▄ĪŻŲõ┤╬Ż¼├┐ę╗éĆąĪ╬─╝■꬚╝ė├ę╗éĆTaskŻ¼Č°Taskåóäėīó║─┘M┤¾┴┐Ģrķg╔§ų┴┤¾▓┐ĘųĢrķgČ╝║─┘Mį┌åóäėTask║═ßīĘ┼Task╔ŽĪŻ▀Ćėąę╗éĆå¢Ņ}Š═╩ŪŻ¼ę“×ķMapTaskĄ─öĄ┴┐╩Ūė╔SplitsüĒøQČ©Ą─Ż¼╦∙ęįė├MR╠Ä└Ē┤¾┴┐Ą─ąĪ╬─╝■ĢrŻ¼Š═Ģ■«a╔·▀^ČÓĄ─Map TaskŻ¼ŠĆ│╠╣▄└Ēķ_õNīóĢ■į÷╝ėū„śIĢrķgĪŻ┼eéĆ└²ūėŻ¼╠Ä└Ē10000MĄ─╬─╝■Ż¼╚¶├┐éĆSprit×ķ1MŻ¼─ŪŠ═Ģ■ėą10000éĆMapTasksŻ¼Ģ■ėą║▄┤¾Ą─ŠĆ│╠ķ_õNŻ╗╚¶├┐éĆSplit×ķ100MŻ¼ätų╗ėą100éĆMap TasksŻ¼├┐éĆMap TaskīóĢ■ėąĖ³ČÓĄ─╩┬Ūķū÷Ż¼Č°ŠĆ│╠Ą─╣▄└Ēķ_õNę▓īó£pąĪ║▄ČÓĪŻ
ĪĪĪĪ2.2 HDFSĖ─▀M
ĪĪĪĪ▒Š╬─īóČÓéĆąĪ╬─╝■┤“░³│╔ę╗éĆÜwÖn╬─╝■Ż¼▀@śėį┌£p╔┘NameNodeā╚┤µ╩╣ė├Ą─═¼ĢrŻ¼╚į╚╗į╩įSī”╬─╝■▀Mąą═Ė├„Ą─įLå¢ĪŻ«öę╗éĆ╬─╝■ĄĮ▀_ĢrŻ¼┼ąöÓįō╬─╝■╩Ūʱī┘ė┌ąĪ╬─╝■Ż¼╚ń╣¹╩ŪŻ¼ätĮ╗ĮoąĪ╬─╝■╠Ä└Ē─ŻēK╠Ä└ĒŻ¼Ę±ätŻ¼Į╗Įo═©ė├╬─╝■╠Ä└Ē─ŻēK╠Ä└ĒĪŻąĪ╬─╝■╠Ä└Ē─ŻēKĄ─įOėŗ╦╝Žļ╩ŪŻ¼Ž╚īó║▄ČÓąĪ╬─╝■║Ž▓ó│╔ę╗éĆ┤¾╬─╝■Ż¼╚╗║¾×ķ▀@ą®ąĪ╬─╝■Į©┴ó╦„ę²Ż¼ęį▒Ń▀Mąą┐ņ╦┘┤µ╚Ī║═įLå¢ĪŻąĪ╬─╝■╠Ä└Ē─ŻēKĄ─┴„│╠╚ńłD3╦∙╩ŠĪŻ
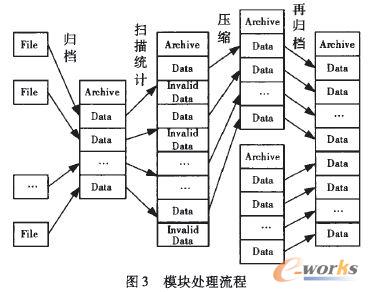
ĪĪĪĪ(1)ąĪ╬─╝■Ą─ÜwÖn╣▄└Ēų„ę¬ė╔ų▄Ų┌ąįł╠ąąĄ─MapReduce╚╬äš═Ļ│╔ĪŻėąęįŽ┬ÄūéĆ╠Ä└Ē┴„│╠Ż║Æ▀├Ķį¬öĄō■ą┼Žó▒ĒŻ¼Įyėŗ╬┤ÜwÖnĄ─ī”Ž¾ą┼ŽóŻ¼░³└©į┌HDFSųąĄ─URI(Uniform Resource IdentifierŻ¼═©ė├┘Yį┤ś╦ųŠĘ¹)Īóī”Ž¾┤¾ąĪĄ╚Ż╗Ė∙ō■┼õų├Ą─ÜwÖn╬─╝■┤¾ąĪŽ▐ųŲŻ¼ī”Įyėŗ╦∙Ą├Ą─ī”Ž¾▀MąąĘųĮMŻ╗īó├┐éĆĘųĮMųąĄ─ī”Ž¾╬─╝■║Ž▓óĄĮę╗éĆÜwÖn╬─╝■ųąŻ╗Ė³ą┬ŽÓĻPī”Ž¾į¬öĄō■ą┼Žó▒ĒųąĄ─öĄō■╬╗ų├├Ķ╩÷ĒŚŻ╗äh│²┼fĄ─ī”Ž¾╬─╝■ĪŻ
ĪĪĪĪ(2)ÜwÖn╬─╝■Ą─ē║┐sų„ę¬ėąęįŽ┬ÄūéĆ╠Ä└Ē┴„│╠Ż║Æ▀├Ķęčäh│²ī”Ž¾▒ĒŻ¼Įyėŗ¤oą¦ī”Ž¾ą┼ŽóŻ╗ī”ė┌╬┤ÜwÖnĄ─¤oą¦ī”Ž¾╬─╝■Ż¼ų▒Įėäh│²Ż╗īóęčÜwÖnĄ─¤oą¦ī”Ž¾░┤ššÜwÖn╬─╝■ĘųĮMŻ╗Įyėŗ╔µ╝░Ą─ÜwÖn╬─╝■Ą─┐šķg└¹ė├┬╩Ż╗Įyėŗ└¹ė├┬╩Ą═ė┌ķōųĄĄ─├┐éĆÜwÖn╬─╝■ųą╦∙ėąėąą¦ī”Ž¾ą┼ŽóŻ╗īóÜwÖn╬─╝■ųąĄ─ėąą¦ī”Ž¾öĄō■║Ž▓óĄĮę╗éĆą┬Ą─ÜwÖn╬─╝■ųąŻ╗Ė³ą┬ŽÓĻPī”Ž¾į¬öĄō■ą┼Žó▒ĒųąĄ─öĄō■╬╗ų├├Ķ╩÷ĒŚŻ╗äh│²┼fĄ─ÜwÖn╬─╝■ĪŻ
ĪĪĪĪ(3)ÜwÖn╬─╝■Ą─į┘ÜwÖnų„ę¬ėąęįŽ┬ÄūéĆ╠Ä└Ē┴„│╠Ż║Æ▀├ĶÜwÖn╬─╝■┴ą▒ĒŻ¼Įyėŗš╝ė├┤┼▒P┐šķgĄ═ė┌ķōųĄĄ─ÜwÖn╬─╝■Ż╗Ė∙ō■ÜwÖn╬─╝■┤¾ąĪ┼õų├ģóöĄŻ¼īóĮyėŗ╦∙Ą├ÜwÖn╬─╝■ĘųĮMŻ╗ĮyėŗĖ„ĘųĮMÜwÖn╬─╝■╔µ╝░Ą─ī”Ž¾Ż╗īó├┐éĆĘųĮMųąĄ─ÜwÖn╬─╝■║Ž▓óĄĮę╗éĆÜwÖn╬─╝■Ż╗īóÜwÖn╬─╝■ųąĄ─ėąą¦ī”Ž¾öĄō■║Ž▓óĄĮę╗éĆą┬Ą─ÜwÖn╬─╝■ųąŻ╗Ė³ą┬ŽÓĻPī”Ž¾į¬öĄō■ą┼Žó▒ĒųąĄ─öĄō■╬╗ų├├Ķ╩÷ĒŚŻ╗äh│²┼fĄ─ÜwÖn╬─╝■ĪŻ
ĪĪĪĪ3ĪóĘų▓╝╩Į╬─╝■ŽĄĮyī”▒╚
ĪĪĪĪ3.1īŹ“ףhŠ│
ĪĪĪĪīŹ“×▓╔ė├▓┘ū„ŽĄĮy×ķCentOS5.4(Red Hat EntERPrise Linux 4.1.2)ŽĄĮyŻ¼╬─╝■ŽĄĮy▄ø╝■Ęųäe×ķHadoop-0.19.2ĪóLustre-1.47ĪóFastDFS-1.23ĪóMogileFS-2.44ĪóMooseFS.1.6.13Ż¼ā╚┤µ║═I/Oąį─▄£yįć▄ø╝■Ęųäe×ķUbench║═IOzoneĪŻ╩╣ė├8┼_PC┤ŅĮ©ŁhŠ│Ż¼ė▓╝■īŹ“×ŲĮ┼_ųąļŖ─XCPU×ķIntel Core 2.66GHzŻ¼Memory×ķ2G/4GŻ¼240Gė▓▒PŻ¼═©▀^100MbpsĮ╗ōQÖCŠųė“ŠW▀BĮėĪŻöĄō■╝»×ķ1ā|éĆ1kBŻ¼2000╚féĆ5kBŻ¼200╚féĆ50kBŻ¼100╚féĆ200kBŻ¼20╚féĆ1MBŻ¼2╚féĆ10MBŻ¼1Ū¦éĆ100MB╬─╝■ĪŻ
ĪĪĪĪ3.2ąį─▄ī”▒╚
ĪĪĪĪ¼FėąĄ─Ė„ĘNĖ„śėĘų▓╝╩Į╬─╝■ŽĄĮyŠ▀ėą▓╗═¼Ą─ąį─▄╠ž³cŻ¼╦³éāĄ─╣”─▄ę▓▓╗▒MŽÓ═¼ĪŻ×ķ┴╦į┌Š▀¾wŅIė“Ė³║├ĄžšŲ╬š║═æ¬ė├▀m║ŽĄ─Ęų▓╝╩Į╬─╝■ŽĄĮyŻ¼▒Š╬─Å─╬─╝■ŽĄĮyĄ─ÄūéĆų„ę¬ĘĮ├µ▀Mąą┴╦įö╝ÜĄ─▒╚▌^Ęų╬÷ĪŻĘų╬÷ĮY╣¹╚ń▒Ē1╦∙╩ŠĪŻ
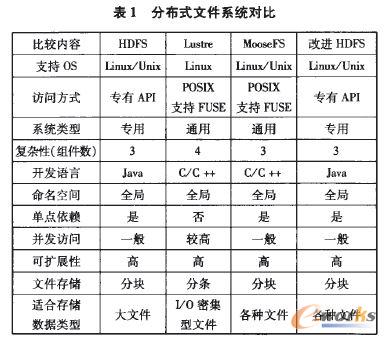
ĪĪĪĪÅ─▒Ē1ųąŻ¼┐╔ęįŪÕ│■Ąž┐┤ĄĮĘų▓╝╩Į╬─╝■ŽĄĮyĖ„ūįĄ─╠ž³cĪŻį┌ų¦│ų▓┘ū„ŽĄĮyĘĮ├µŻ¼Ė„éĆŽĄĮyČ╝ų¦│ųLinux▓┘ū„ŽĄĮyŻ¼▓┐ĘųŽĄĮy▀Ćų¦│ųUnix▓┘ū„ŽĄĮyŻ╗į┌ŽĄĮyŅÉą═ĘĮ├µŻ¼HDFSĄ╚īŻė├Ęų▓╝╩Į╬─╝■ŽĄĮyŠ▀ėą▌^║├Ą─ąį─▄║═▌^Ą═Ą─Å═ļsČ╚Ż¼Č°═©ė├Ęų▓╝╩Į╬─╝■ŽĄĮyį┌įLå¢ĘĮ╩Į╔Ž╠ß╣®ś╦£╩APIŻ¼▀Ćų¦│ųFUSEŻ¼┐╔ęį╣▄└ĒĘų▓╝╩Į╬─╝■ŽĄĮy╚ń═¼╣▄└Ē▒ŠĄž╬─╝■ŽĄĮyę╗śėŻ╗į┌╚▌ÕeĘĮ├µŻ¼Lustreį┌┤µā”Ę■äšŲ„╔Ž╩╣ė├┤┼▒PĻć┴ąŻ¼åóė├éõė├į¬öĄō■╣▄└ĒĘ■äšŲ„Ż╗HDFS║═MooseFSį┌┤µā”Ę■äšŲ„╔ŽéõĘ▌╬─╝■Ż¼į┌į¬öĄō■╚šųŠĘ■äšŲ„╔ŽéõĘ▌╚šųŠŻ¼ė├ė┌╗ųÅ═į¬öĄō■Ę■äšŲ„Ż╗FastDFS║═MogilesFSę▓į┌┤µā”Ę■äšŲ„╔ŽéõĘ▌öĄō■Ż¼į┌ČÓéĆš{Č╚Ę■äšŲ„╔Ž▓╔ė├žō▌dŠ∙║Ō▓▀┬įĪŻ╦³éāę▓ėą║▄ČÓŽÓ╦ŲĄ─ĄžĘĮŻ¼▒╚╚ńČ╝ų¦│ųį┌Linux▓┘ū„ŽĄĮy╔Ž▓┐╩Ż¼Č╝▓╔ė├╚½ŠųĄ─├³├¹┐šķgŻ¼Č╝ėą║▄║├Ą─┐╔öUš╣ąįĄ╚ĪŻ
ĪĪĪĪį┌į¬öĄō■╣▄└Ē╣سcĘĮ├µŻ¼FastDFS║═MogileFSėąČÓéĆš{Č╚Ę■äšŲ„Ż¼▓ó░lįLå¢─▄┴”▒╚▌^═╗│÷Ż¼Lustreėąā╔éĆį¬öĄō■╣▄└ĒĘ■äšŲ„Ż¼Ųõųąę╗éĆ╩Ū╗ŅäėĘ■äšŲ„Õ┤ÖC║¾ūįäėåóäėĄ─║¾éõĘ■äšŲ„Ż¼ėąą¦ĄžĮŌøQ┴╦å╬³cę└┘ćå¢Ņ}Ż¼Č°HDFSĪóMooseFS║═Ė─▀MHDFSų╗ėąę╗éĆį¬öĄō■╣▄└ĒĘ■äšŲ„Ż¼┤µį┌å╬³cę└┘ćå¢Ņ}Ż¼Č°Ūęį¬öĄō■Č╝▒Ż┤µį┌ā╚┤µųąŻ¼«ö╬─╝■öĄ┴┐│¼▀^ę╗Č©ĘČć·ĢrŻ¼▀ĆĢ■ė÷ĄĮā╚┤µŲ┐ŅiŻ╗į┌į¬öĄō■š╝ė├ā╚┤µĘĮ├µŻ¼HDFS├┐éĆ╬─╝■į¬öĄō■š╝ė├ā╚┤µ┤¾╝s150Ī½200Byteų«ķgŻ¼MooseFS├┐éĆį¬öĄō■┤¾╝s300ByteŻ¼Č°ŪęļSų°╬─╝■öĄ┴┐į÷╝ėā╚┤µš╝ė├ę▓įĮ┤¾Ż╗Lustreį¬öĄō■ų╗š╝ė├4Byteū¾ėęŻ¼«ö╬─╝■öĄ┴┐│¼▀^2000╚fŻ¼ā╚┤µš╝ė├ę▓ļSų«į÷┤¾Ż╗Ė─▀MHDFSā╚┤µš╝ė├┼c╬─╝■öĄ┴┐ĻPŽĄ▓╗┤¾Ż¼ļSų°╬─╝■öĄō■į÷┤¾╔į╬óį÷ķLŻ¼«ö╬─╝■öĄ┴┐▀_ĄĮ6000╚fŻ¼ā╚┤µąį─▄┼cLustre│ųŲĮĪŻį¬öĄō■ā╚┤µš╝ė├Ūķør╚ńłD4╦∙╩ŠĪŻ
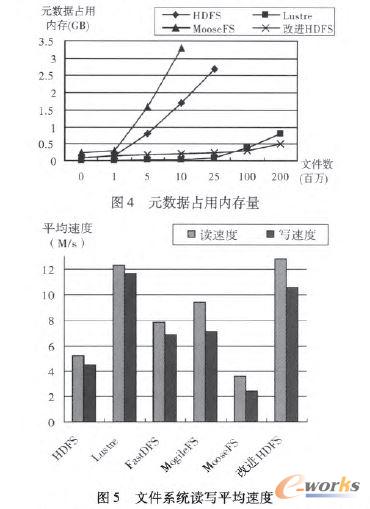
ĪĪĪĪį┌╬─╝■┤µ╚ĪĘĮ├µŻ¼HDFS║═MogileFS═©│Żė├üĒ┤µā”ņoæB┤¾╬─╝■Ż¼Č°MooseFS║═Ė─▀MHDFS┐╔ęį┤µā”Ė„ĘN╬─╝■Ż¼┤µā”Ą─╬─╝■ę╗░Ń▓╗ąĶꬹ▐Ė─Ż¼ų╗╠ß╣®Ž┬▌dĘ■䚯╗FastDFSę╗░Ńė├ė┌┤µā”ę¶ŅlĪóęĢŅl║═╬─ÖnĄ╚Ż¼╬─╝■▒╚▌^ąĪŻ¼╦∙ęį▓╗ĘųēK┤µā”╬─╝■Ż¼ęį╬─╝■×ķå╬╬╗üĒ┤µā”Ż╗Č°LustreęįĘųŚlĄ─ĘĮ╩Į┤µā”╬─╝■Ż¼ų„ę¬┤µā”├▄╝»ą═öĄō■Ż¼▀MąąĖ▀ąį─▄ėŗ╦ŃŻ╗ŽÓī”ė┌HDFSŻ¼Ė─▀MĄ─HDFSŲĮŠ∙ūxīæ╦┘Č╚į÷╝ė┴╦ę╗▒Čū¾ėęŻ¼ūx╦┘Č╚┬įĖ▀ė┌LustreŻ¼Ą½īæ╦┘Č╚┬į▀dė┌LustreĪŻ╬─╝■ŽĄĮyūxīæŲĮŠ∙╦┘Č╚╚ńłD5╦∙╩ŠĪŻ
ĪĪĪĪ4ĪóĮY╩°šZ
ĪĪĪĪįŲ┤µā”╩ŪĮ³─ĻüĒ▒╗ÅVĘ║æ¬ė├Ą─ą┬╝╝ągŻ¼┐╔ęįÅVĘ║æ¬ė├ė┌ę╗ą®ųžę¬Ą─ŅIė“Ż¼╚ńÜŌŽ¾ŅIė“ĪóęĢŅlĘųŽĒŠWšŠĄ╚Ż¼ę“┤╦Ęų▓╝╩Į╬─╝■ŽĄĮyę▓ę²üĒ┴╦Ė³ČÓĄ─ĻPūóŻ¼į┌īWągĮń║═╣żśIĮńČ╝ėą║▄ČÓĄ─Ęų▓╝╩Į╬─╝■ŽĄĮyĪŻ╚ń║╬▀xō±║Ž▀mĄ─Ęų▓╝╩Į╬─╝■ŽĄĮy╩Ūę╗éĆ┤¾å¢Ņ}Ż¼▒Š╬─į┌╝▄śŗĪóįLå¢ĘĮ╩ĮĪó╬─╝■┤µā”ĘĮ╩ĮĄ╚ĘĮ├µ▀Mąą┴╦įö╝ÜĄ─ī”▒╚Ż¼▓óī”HDFSį┌I/Oąį─▄ĘĮ├µ▀Mąą┴╦Ė─▀MŻ¼Ė∙ō■▀@ą®ą┼ŽóŻ¼ė├æ¶┐╔ęį║Ž└ĒĄž▀xō±Ęų▓╝╩Į╬─╝■ŽĄĮyĪŻļm╚╗Ė„éĆĘų▓╝╩Į╬─╝■ŽĄĮyėąĖ„ūįĄ─ā×ä▌║═╠ž³cŻ¼Ą½▀Ćėąę╗ą®žĮ┤²ĮŌøQĄ─å¢Ņ}Ż¼Ž┬ę╗▓Įīó▀Mę╗▓ĮĮŌøQå╬į¬öĄō■╣▄└ĒĘ■äšŲ„ę└┘ćå¢Ņ}ĪóČÓš{Č╚Ę■äšŲ„žō▌dŠ∙║Ōå¢Ņ}ĪóŽĄĮy╚▌ÕeÖCųŲ║═▓ó░lūxīæĄ╚ĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.lukmueng.com/
▒Š╬─ś╦Ņ}Ż║įŲ┤µā”╬─╝■ŽĄĮyī”▒╚
▒Š╬─ŠWųĘŻ║http://www.lukmueng.com/html/support/11121511639.html